
リファクタリングをPythonで実践!基本手法とコード例・注意点まで
2023.09.07
スマートフォンだけでなく、スマートスピーカーをはじめとする「スマート家電」が続々と登場し、画面やボタンではなく「声」で操作する家電が増えてきました。
その裏では、「音声認識」という技術が活用されています。
本記事では、音声認識について詳しく解説していきます。

音声認識は、人の声を取り込み、発言内容を文字として認識する技術を指します。
Google HomeやAlexaといった声で操作するスマートスピーカーも、音声認識の技術が活用されています。
現在の音声認識では、裏には機械学習(AI)が活用されていることが多くなりました。
それでは、音声認識の歴史について簡単に紹介します。
スマートスピーカーが登場する以前にも、声で操作する電化製品が存在しました。それが「カーナビ」です。
音声で住所や建物の名称を入力することで、その声を認識して目的地に設定してくれます。
しかし、カーナビの認識精度はお世辞にも良いとは言えず、何度も言い直すこともあるでしょう。
これは、機械学習ではなく「音声パターンのマッチング」という技術を用いているためです。
音声に限らず、「音」は波形で表せます。
音声パターンのマッチングでは、波形の周波数を検出し、「この音は”あ”と発言している」といったような認識をするのです。
例えば、「とうきょうと」であれば、「と」「う」「きょ」「う」「と」といったように、一音ずつに分解して音読みを理解し、それにマッチする住所を検索して提示するようになっています。
音声認識に機械学習が使われ始めて、音声の認識精度は格段に向上しました。
膨大な機械学習モデルを使用することで、性別や年代、地域性といった様々なパターンに対応できるようになりました。
カーナビの場合、行き先といえば住所か建物、ランドマーク名といったようにある程度決まっているものがほとんどでした。
しかし、スマートスピーカーの場合には様々な指示を受け付けます。
例えば、アラームをかけたり、誰かと連絡をしたり、様々な使い方を可能としたのがスマートスピーカーの最大のメリットです。
このように、「汎用的」な音声認識をする上での立役者がAI、すなわち機械学習なのです。
音声認識に機械学習を活用することで、より精度の高い音声認識が可能となりました。
それでは、音声認識がどのように行われているのかについて詳しく解説していきます。
まずは、音のデータを分析し、「音声」の部分を取り出しデータ化します。
よほどの録音スタジオでない限り、生活音やBGMなど、何かしらの雑音がノイズとして含まれます。
この雑音を取り除き、きれいな「音声」部分を取り出すのが音響分析の作業です。
人には出せない高音域または低音域をカットしたり、メインとなる音声以外の小さな音をカットしたりするような作業を行っていきます。
音響分析した音声データは、次に音響モデルに分解していきます。
音響モデルとは、「音響」としての特徴を表したもので、音声データの「音素(音としての最小単位)」に分解します。
例えば、日本語の場合には、ローマ字に直すとわかりやすいでしょう。
「おはよう」は、「o-ha-yo-u」といったように、「母音」と「子音」を基準として一文字を検出できます。
つぎに、この一音、または連続した音をもとに辞書から意味のある単語に変換していきます。
例えば日本語の場合、「う」と「お」は聞き間違いが多く、実際に「おはよう」を「おはよお」と発音している人もいますよね。
その際、音声認識モデルが「おはよう」という単語を辞書に持っており、かつ「お」と「う」が間違いやすいことを知っていれば、音響モデルで「おはよお」と認識していたとしても、パターンマッチの際に自動で「おはよう」に変換します。
パターンマッチでは単語ごとに補正していきますが、言語モデルでは、さらに「文章」として成り立つように補正していきます。
例えば、「おはよう」の後に続く言葉といえば「ございます」のように、次につながる言葉はある程度予想できるでしょう。
音声認識に使用される機械学習モデルは、このような文章のつながりを大量に学習しており、「意味の通じる文章」を作れるように補正します。
この言語モデルが優秀であれば、音響・パターンマッチで少し違う単語に変換されたとしても、意味が通じるように自動で変換されるのです。
特に、日本語の場合には「同音異義語」が大量に存在します。
「おはようございます、きょうはいいてんきですね」
という発音を、
「おはようございます、教はいい転機ですね」
ではなく、
「おはようございます、今日はいい天気ですね」
と正しく変換できるのも、この言語モデルによるものです。
そのほか、人がしゃべる内容を音声認識する際には特に、「あー、」や「えーっと」といった間投詞が多く登場します。
優秀な言語モデルであれば、これらの単語を自動で認識し、除外することも可能です。
近年の音声認識の技術は進歩を続けており、現在では様々な業界やサービスで活用されています。
クレジットカード業界をはじめとする金融業では、顧客と電話でやり取りを行う「コールセンター業務」が存在します。
それまでは、顧客と会話していた内容を逐次メモしていたのですが、会話が長くなるほど入力が大変でした。
とあるクレジットカードの会社では、顧客の音声を録音するだけでなく、リアルタイムに文字起こしをすることで、聞き逃しや聞き間違いを防止することが可能となりました。
自治体に限らず、会議をした場合にはその内容を残すために「議事録」を作成するのが通例です。
とある自治体では、会議の議事録を作成するために膨大な時間をかけており、特に参加者が多い場合には会議時間の10倍近い時間をかけて議事録を作成していました。
そこで、音声認識を活用した議事録作成ソリューションを導入することで議事録作成にかける時間を短縮できました。
高機能な音声認識ソフトウェアであれば、「誰が発言したか」も含めて認識できるため、発言内容だけでなく発言者も自動で認識できます。
録音した内容を聞き返す必要もないため、議事録作成者の作業時間だけでなくストレス削減にも役立っています。
医療機関でも電子カルテの導入による電子化が進んでいる中で、特に年配の先生からは「慣れないパソコン操作ではかえって時間がかかってしまう」という意見が多かったようです。
そこで、電子カルテへの入力を音声で行うシステムを導入しました。
パソコンのキーボードで打ち込むよりも圧倒的に早く、医療関係に特化した言語モデルを使用することで非常に精度の高い音声認識が可能となりました。

音声認識を実際に行おうとする場合には、どのような知識が必要なのでしょうか。
自分で音声認識を実現しようとした場合に必要な知識を紹介します。
「機械学習といえばPython」と言われているほど、Pythonの知識は必須といえます。
音声ファイルの操作や、APIを使用する際にPythonのコードを記述することになるため、基本的な構文はマスターしておきましょう。
前述の音響分析や音響モデルを作成する際には数学の知識が必要ですし、パターンマッチを理解するためには統計学の知識が必要です。
とはいえ、昨今では高度な音声認識APIが提供されているため、数学の知識がなくてもある程度精度の高い音声認識が実現できるようになっています。
方言など、地域に特化したイントネーションのチューニングを目的とする場合には、これらの知識が必要となってくるでしょう。
それでは、実際にPythonで音声ファイルを読み込む方法を紹介します。
今回は、Pythonの音声認識ライブラリを利用して文字起こしをしてみましょう。
まずは、事前準備から始めます。
今回はPythonで音声認識を実施するため、Pythonのインストールをしておきましょう。
すでにPythonがインストールされている場合には、この手順はスキップしてください。
インストールに成功しているか確認するには、以下のコマンドを実行します。
python3 --version
Python 3.9.6Pythonは標準で音声認識を有していませんので、必要なライブラリをインストールしていきます。
今回は、音声認識ライブラリである「SpeechRecognition」を使用します。
$ pip3 install SpeechRecognitionまた、後述のマイク入力のために「pyaudio」も合わせてインストールしておきます。
$ pip3 install pyaudioさらに今回はGoogleのAPIを使用して文字起こしを行うため、下記のライブラリも合わせてインストールしておきましょう。
$ pip3 install google-cloud-speech google-api-python-client oauth2clientmacOSを使用している場合、pyaudioのインストールでエラーになる場合があります。
その場合には、以下の手順を実行してください。
(1) ${HOME}/.pydistutils.cfgを編集
[build_ext]
include_dirs=/opt/homebrew/include
library_dirs=/opt/homebrew/lib(2) portaudioのインストール
brew install portaudio準備が整ったら音声を取り込んで認識させてみましょう。
まずは、音声ファイルを用いて音声認識をする方法から紹介します。
今回は、音声ファイルをあみたろの声素材工房よりダウンロードして認識させてみましょう。
サイトの中から、「はじめまして」をダウンロードします。(ブラウザで再生が始まる場合には、右クリックメニューからダウンロードできます)
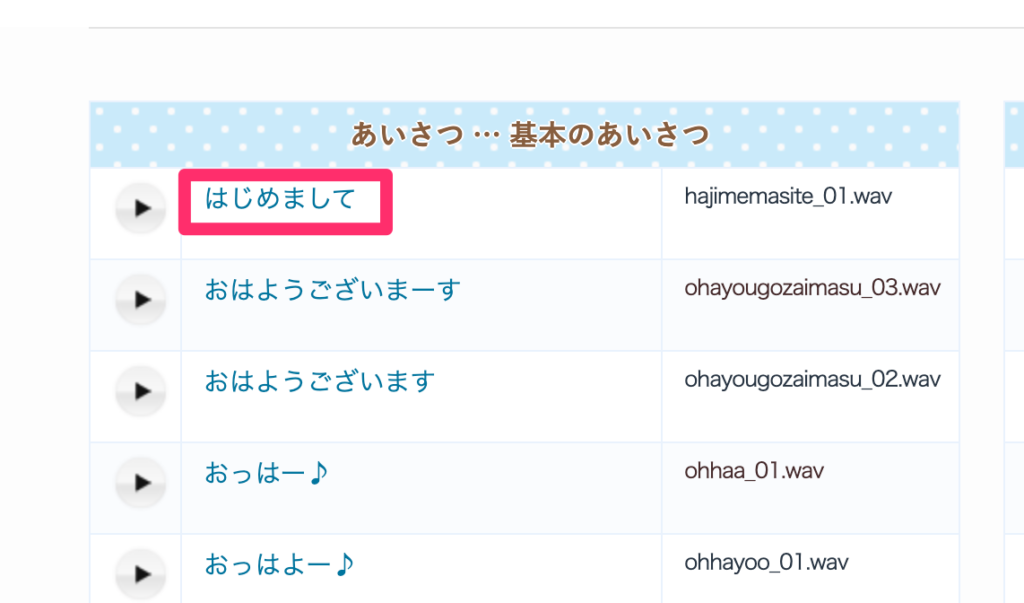
ダウンロードが完了したら、ダウンロードした音声ファイルと同じ場所で下記のPythonコードを実行してみましょう。
import speech_recognition as sr
r = sr.Recognizer()
# 音声ファイルを指定
with sr.AudioFile('hajimemasite_01.wav') as source:
audio = r.listen(source)
# GoogleのAPIを利用して文字起こしする
text = r.recognize_google(audio, language='ja-JP')
print(text)実行すると、以下のように出力されます。
初めましてこのように、「初めまして」と変換されて認識されていることがわかります。
マイクから入力することで、リアルタイムに音声認識をすることも可能です。
以下のサンプルコードを実行してみましょう。
import speech_recognition as sr
r = sr.Recognizer()
with sr.Microphone(sample_rate=16_000) as source:
print("なにか話してください")
audio = r.listen(source)
print("音声を取得しました")
recognized_text = r.recognize_google(audio, language='ja-JP')
print(recognized_text)コードを実行し、
なにか話してくださいと表示されたら、好きな言葉を話してみましょう。
今回は例として「こんにちは、今日はいい天気ですね」と発言してみてください。
すると、以下のように出力されます。
音声を取得しました
こんにちは 今日はいい天気ですね最後に出力された、「こんにちは 今日はいい天気ですね」が音声認識で認識された文字となります。
※掲載された社名、製品名は、各社の商標及び登録商標です。






 アジャイル開発 (9)
アジャイル開発 (9)