
リファクタリングをPythonで実践!基本手法とコード例・注意点まで
2023.09.07

機械学習、AI、ディープラーニング。いろいろな言葉が飛び交いますが、いずれもAIに含まれる概念です。まずはこの3つの違いから解説していきます。
AI(Artificial Intelligence)とは、日本語では「人工知能」です。日本人は「人工知能」というと真っ先に「ドラえもん」のようなヒト型の知能を思い浮かべるかもしれませんが(ドラえもんはネコ型ロボットですが)、そういうAIは、「汎用型AI」と呼ばれます。
「汎用型AI」は、人間と同じように、あらゆる事象に対して考えてアクションを起こすことのできる、総合型のAIです。これに対し、今実現されているAIとは、特定の問題を解くことに特化しています。
自分が専門とする問題に対しては、人間よりはるかに早く、高精度で解くことができるようになっています。そのAIを開発する際に用いられているAIを訓練する手法の一つが「機械学習」です。
AIについて学びたい人におススメ! 【AI入門資料】サクッとわかるAIはじめの一歩-無料ダウンロード
「機械学習」はそれほど新しい概念ではありません。理論だけなら1950年代からありました。それがなぜ近年になってやっと実用化されたのかと言えば、誰もがパソコンを使うようになったこと、スマホやIoT機器が一般的になったことで、「機械学習」に欠かせない「ビッグデータ」が容易に集められるようになったことがまず一つ。
二つ目に、コンピュータの処理能力が劇的に向上したこと。この二つにより、「機械学習」の実施が容易になったことが背景にあります。そして2006年、「機械学習」の一つの手法として「ディープラーニング」が発明されます。
「ディープラーニング」は、「ニューラルネットワーク」と呼ばれる、人間の神経組織を模した学習方法を使い、ざっくりいうと「勝手に」AIが学習します。
「ニューラルネットワーク」は、この記事で紹介するPythonの機械学習手法にも使われています。ただ理論的には多少難しいものではありますので、この記事ではサンプルコードを示すにとどめ、詳細な理論は措いておきます。
それでは機械学習の代表的な学習方法である
について見ていきましょう。
データに「正解」を持たせて(たとえば巨峰かマスカットかを識別するAIを作りたいなら、膨大なブドウのデータに一つ一つ「巨峰」「マスカット」と正解をつけて)そのデータがなぜその正解に行き着くのかをAIが学習する方法です。
学習するときの手法には様々なものがあり、またどの特徴に着目するか(「特徴量」と呼ばれます)にも様々なものがあります。高度な数学を駆使して学習方法(「モデル」と呼ばれます)は構築されています。
データを識別する方法をAI自らが考案します。人間が思いつかない識別をAIに出させるときのために使います。例えば、膨大なツイート群の自然言語解析などに使われます。NHKでたまに放送しているのですが、膨大な自然言語の文章を解析して単語間の連関度を示したりしています。人間なら思いもつかない連関が発見されたりします。
AIが、とある法則で正解を導き出したときにその法則に対し賞を与え、不正解の時に罰を与えることにより、より正解に導けるように訓練していく方法です。
例えば、Webサイトで広告をクリックさせたら、サイト運営者にとっては正解です。AIが、広告をクリックさせやすい仕組みを考えられれば、それは賞になります。反対に、クリックさせられなかったら罰です。
では、なぜPythonは機械学習に向いているといわれるのでしょうか? その理由を4つご紹介します。
そもそもPythonが注目されたきっかけは機械学習の開発言語がPythonの独擅場たったからでした。この流れは今も続いていて、既に、多くの企業の業務システムのAIの開発言語、多くのサービスのAIの開発言語はPythonです。これらのAIを更に機械学習させて改良していく場合、開発言語はPython一択となりますね。
また、Pythonの特徴として、大量のデータを扱う機械学習のコードでもシンプルでわかりやすく書けるという特徴があります。機械学習に限らないPythonの特徴です。Pythonは大量のデータを扱うのに向いています。このことは機械学習にPythonが採用される最大の理由です。
詳細は後述しますが、Pythonは長年機械学習で使用されているので、ライブラリも豊富にあります。ライブラリの存在は開発を格段に楽にしてくれます。
Python公式ドキュメント、Web上の記事、本など、Pythonで機械学習をするときに参考にするべきドキュメントは実に豊富にそろっています。これはPythonが長年機械学習で使用されてきたからというのが大きいです。また、Python自体もメジャーな開発言語なので、Pythonのドキュメントも豊富に揃っています。
機械学習はすでに私たちの身の回りのいろいろなサービスを構成しています。
筆者自身も驚いたのですが、機械学習を利用して、モザイクがかかった顔写真から元の顔を再現する技術があるそうです。これなど画像解析の最先端です。
ここまでいかなくても、その画像の中に何が含まれているかなどは比較的簡単に解析できます。スマホに搭載されていて、若い女性がよく使用している、目を大きく見せるAIなどもこの技術です。
画像解析についてはこちらの記事でも触れているので、参考にしてください。
「テキストマイニング」とは、自然言語解析のことです。膨大なアンケート結果を有機的に解析したりできます。
音声認識もAIです。iPhoneのSiri、EchoのAlexaなどは自然言語をある程度理解し、また発声します。膨大な量の音声データで学習し、人間と会話できるように訓練されています。これらのAIは、使っているうちに使用者の声にますます馴染むようになり、使用者に最適化されていきます。使いながらも学習しているのです。
天気予報に機械学習は使用されています。過去の膨大なデータを基にして、未来の天気を予測するのです。ここ数年、天気予報の精度が格段に上がりました。
機械学習を行うための基本的な流れについてわかりやすくご紹介したいと思います。どこでプログラミングが出てくるのか、意識して読み進めていってください。
まずはデータを準備します。有象無象のデータは全て数字や文字列となります(画像は数字の集合体です)。どういう形式のデータを集めるか決めて、データを集めます。
機械学習を始める前にデータをある程度分析する必要があります。あまりにも例外が多い場合はいい学習ができませんから、それは可視化して確認して取り除きます(その特徴は切り捨てて、学習の時に考慮しない)。
ここからがコーディングです。データを使用するライブラリに適した形式に整えます。これに案外時間がかかります。
③とも密接に関わるのですが、どんな「モデル」をつかったら一番よく学習するかを考え、「モデル」を組み立て、実際に学習させます。
学習させたら必ず検証します。そして、その「モデル」が適しているかどうかを評価します。いい結果が出ていないと判断したら④に戻り、モデルを構築し直します。通常、この流れは何十回も繰り返します。
上述した通り、Pythonには機械学習で活用できるライブラリが豊富に用意されています。代表的なものをご紹介します。
Numpyは、多次元配列(数学の「行列」)を扱える数値計算ライブラリです。「行列」は、機械学習において計算の基礎となる概念で、機械学習のライブラリはどれもNumpyを使用しています。また、Numpyを使用し、データの前処理を行います。
ただ、Numpyには、配列の要素の型が全て同じでなくてはならないという大きな制約があります。その制約がないのがpandasです。pandasではデータベースをSQLで処理するがごとく、表形式のデータを関数で処理することができます。そのため、Numpyと同じく機械学習のライブラリが使用するほか、データの前処理に使われます。
matplotlibはグラフを描画するためのライブラリです。Jupyter上などに、簡単な命令でグラフを描画することができます。Excelのグラフ描画のように多彩な表現ができます。データや学習結果の可視化に使います。
seabornもグラフを描画するためのライブラリです。matplotlibの強化版です。実際、matplotlibがseabornの内部で動いています。matplotlibよりも簡単な命令で、かつより多彩なグラフが描画できるのが特徴です。matplotlibと同じく、データや学習結果の可視化に使います。
scikit-learnは学習させるためのライブラリです。機械学習においてはメインのライブラリです。scikit-learnで学習させることが可能なモデルは例えば以下があります。
mecabとは、形態素エンジンです。形態素とは、自然言語で意味を持つ最小単位です。mecabは自然言語を形態素に分割してそれぞれの品詞等を判別します。このmecabのPythonでのライブラリがmecab-pythonです。テキストマイニングに使用されます。
Gensimはトピック分析のエンジンです。トピック分析とは、与えられた文章がどのトピックに属するかを分類する手法のことです。つまり、文章の属する文脈を判断できます。テキストマイニングに使用されます。
XGBoostとLightBGMは、scikit-learnのところで少し触れた、決定木モデルの一種です。決定木モデルで学習させるためのライブラリです。
Kerasは、「ニューラルネットワーク」を実装するためのライブラリです。例えばTensorflowなどと共に使います。Tensorflowは「テンソル行列」を計算するためのライブラリで、その計算はニューラルネットワークにおいて重要なものです。
PyTorchも学習をさせるためのライブラリです。2017年にFacebookによってリリースされた、比較的新しいライブラリです。機械学習で出来ることは基本的にPyTorchでできます。
さあ、いよいよPythonのライブラリを実際に動かしてみましょう。
ここからはライブラリを使ってみますが、機械学習は使うライブラリが多いので、まず周辺のライブラリから説明します。まずはNumpyです。
Numpyは配列が計算できるので、配列にデータを格納しておき、そこから統計処理をすることができます。たとえば、cov関数で共分散行列が計算できます。共分散行列は以下のような構造をしています。
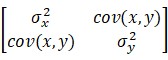
この行列の「1行2列」か「2行1列」がもとめる共分散です。共分散とは、「どれだけ値が散らばっているか」という統計指標です。値が大きいほど値が散っています。サンプルコードは
import numpy as np
xs = [2, 5, 9, 1, 3]
ys = [1, 3, 0, 1, 2]
np.cov(xs, ys, ddof=0)
array([[ 8. , -0.8 ],
[-0.8 , 1.04]])
です。xs、ysというデータの共分散を計算させました。-0.8になっています。ddof=0とは、共分散の計算時に、単純にデータの個数で割るための指定です。
次にmatplotlibです。matplotlibはグラフが描画できます。正規分布のグラフを描画してみましょう。
import matplotlib as mpl
mpl.use('Agg')
import matplotlib.pyplot as plt
from scipy.stats import norm
import numpy as np
xs = np.linspace(-10, +10, 201)
ys = []
for x in xs:
ys.append(norm.pdf(x, 0, 1))
plt.plot(xs, ys)
plt.savefig("正規分布.png")
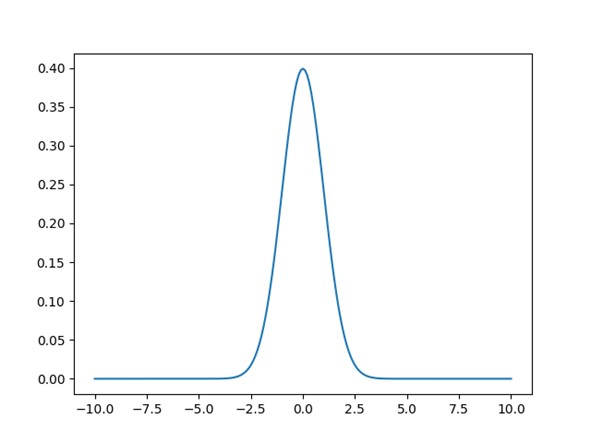
mpl.use('Agg')は、matplotlibで画像ファイルを作るためのおまじないです。
xs = np.linspace(-10, +10, 201)で、-10から+10の間に、201個の等間隔の値の配列を作っています。これがx軸の計算する座標になります。
for x in xs:
ys.append(norm.pdf(x, 0, 1))
x軸の計算する座標それぞれに、正規分布の値を計算しています。pdfとは「確率密度変数」という意味です。引数の意味は難しいので割愛します。その計算したx、yを
plt.plot(xs, ys)で描画します。matplotlibの描画はただこれだけです。
plt.savefig("正規分布.png")で保存します。
さて機械学習のscikit-learnです。まずサンプルコードを示します。
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris_dataset = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], random_state=5)
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
print(iris_dataframe)
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
for i,j in zip(y_test,y_pred):
if i!=j:
print("真:",iris_dataset['target_names'][i],',予測:',iris_dataset['target_names'][j])
結果画面は
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
0 5.0 3.5 1.3 0.3
1 6.4 3.2 5.3 2.3
2 5.8 2.7 5.1 1.9
3 5.6 2.5 3.9 1.1
4 5.1 3.5 1.4 0.3
.. ... ... ... ...
107 4.4 2.9 1.4 0.2
108 6.1 2.8 4.7 1.2
109 6.7 3.3 5.7 2.5
110 7.7 2.6 6.9 2.3
111 5.7 2.8 4.1 1.3
[112 rows x 4 columns]
検証は38個
真: versicolor ,予測: virginica
真: virginica ,予測: versicolor
真: versicolor ,予測: virginica
一行一行解説します。
iris_dataset = load_iris()これはscikit-leranに組み込まれている「百合の種類を学習するためのデータセット」を読み込んでいるだけです。
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], random_state=5)X_train:学習要データセット
X_test:検証用データセット
y_train:学習用結果セット
y_test:検証用結果セット
です。X_trainとy_trainで教師あり学習をさせて、X_testで検証してみて、y_testで正誤を判定します。
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
print(iris_dataframe)
pandasのDataFrameを作成しています。この前処理が必要です。作成されたDataFrameは結果画面に表示されています。
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train, y_train)
ここがscikit-learnで機械学習させている部分です。k-近傍法を用いて、fitで学習させます。
y_pred = knn.predict(X_test)そして検証し、結果をy_predに代入します。
for i,j in zip(y_test,y_pred):
if i!=j:
print("真:",iris_dataset['target_names'][i],',予測:',iris_dataset['target_names'][j])
間違ったものだけ表示させています。38個中、3個しか間違っていませんね。
AIについて学びたい人におススメ! 【AI入門資料】サクッとわかるAIはじめの一歩-無料ダウンロード
6で見た通り、機械学習はこのような一連のライブラリを使って行います。前処理、学習、表示と使うべきライブラリは多く、それらへの深い知識が求められます。この記事で取り上げたライブラリで言えば、Numpyは前処理、scikit-learnは学習、matplotlibは表示です。
更に、機械学習へのモデルへの深い理解も欠かせません。例えばディープラーニングをするなら、ニューラルネットワークの深い数学的理解が欠かせません。数学力は機械学習の基礎知識です。大学院レベルの数学が求められます。なので、そう簡単にできるものではないです。
実際、データサイエンティストの報酬は月100万円くらいが相場です。言い換えれば、高い壁をクリアすれば、それくらいの月収にはなるということです。 だから、トライする価値はあります。あなたもぜひ機械学習にトライしてみてください。







 アジャイル開発 (9)
アジャイル開発 (9)