
リファクタリングをPythonで実践!基本手法とコード例・注意点まで
2023.09.07
この記事ではscikit-learnを用いた回帰分析とクラス分類の方法を紹介します。
環境構築からサンプルまでありますのでぜひ最後までご覧ください。

ランダムフォレストを理解するうえで必要な用語について図解を交えて説明し、ランダムフォレストとはなにかを紹介します。
決定木とは分類や回帰などのルールをツリーで表したものです。
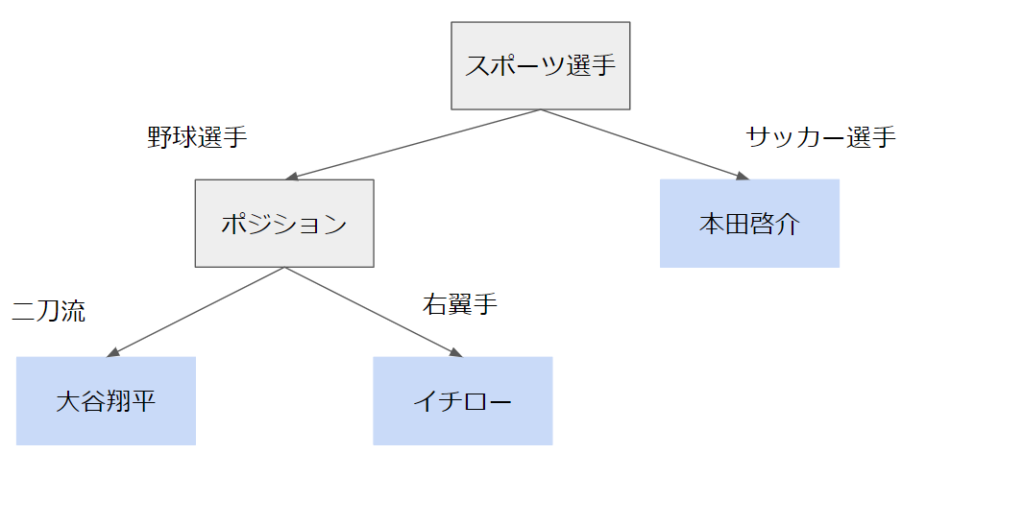
上の例ではどのような条件で分類しているかを図示しています。
アンサンブル学習とは様々な機械学習モデルを組み合わせ、より精度の高いモデルを構築する学習方法です。
機械学習には様々なモデルが存在し、各モデルは異なる方法でデータに対する予測を行います。
そのためモデル毎に異なる結果を導きます。各モデルの結果を組み合わせることで、精度の高い予測が可能なのです。
ランダムフォレストとは複数の決定木でアンサンブル学習するモデルです。
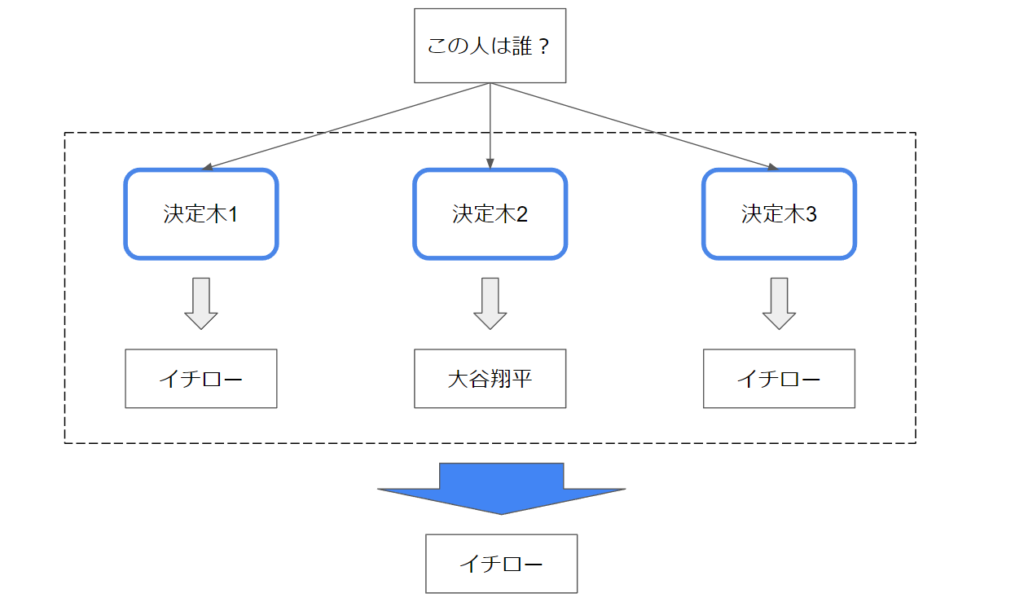
上の画像のようなイメージで、複数の決定木で多数決を取り、より精度の高い予測を行います。
ここからはPythonでランダムフォレストを実装するにあたって必要な事前知識を紹介していきます。
scikit-learnとはPythonの機械学習モデルを提供するライブラリです。オープンソースで公開されており、個人や商用を問わず利用可能になっています。
人気言語のPythonですが、機械学習は特に人気の領域なので現在も活発に開発されており、ドキュメントが豊富なのが特徴です。
様々な機械学習モデルを似たような書き方で書けるので、学習コストを抑えて本格的な機械学習ができます。
また、大きな特徴はサンプルのデータセットが付属していることです。こちらを活用することですぐに機械学習に取り組めます。
初めにscikit-learnのインストール方法を紹介します。
scikit-learnはPythonのパッケージ管理ツールpipでインストールできます。
下記コマンドを実行します
pip install scikit-learnscikit-learnのランダムフォレスト用クラスは2つあります。2つの特徴を抑えて適切に使い分けましょう。
RandomForestClassifierは分類用クラスです。OKかNGかなど判断する機械学習をする際に利用します。
RandomForestRegressorは回帰用クラスです。数値を予測する機械学習をする際に利用します。

ここからは実際にプログラムを作成していきます。アヤメの4つの要素を用いて種類を当てるモデルを作成してみましょう。
前述の通り、scikit-learnにはサンプルのデータセットが付属しています。今回はその中のアヤメの計測データを使用します。
今回使用するデータの概要です。
・データ件数:150件
・データ次元数:4(各要素が4項目)
実際にデータを見ていきましょう。
from sklearn.datasets import load_iris
iris_list = load_iris()
print(iris_list)
# {'data': array([
# [5.1, 3.5, 1.4, 0.2],
# [4.9, 3. , 1.4, 0.2],
# [4.7, 3.2, 1.3, 0.2],
# [4.6, 3.1, 1.5, 0.2],
# [5. , 3.6, 1.4, 0.2],
# [5.4, 3.9, 1.7, 0.4],
# [4.6, 3.4, 1.4, 0.3],
# [5. , 3.4, 1.5, 0.2],
# [4.4, 2.9, 1.4, 0.2],
# [4.9, 3.1, 1.5, 0.1],
# [5.4, 3.7, 1.5, 0.2],
# ...
# 'target': array([0, 0, 0, 0, 0, 0,
# …
# 1, 1, 1, 1,
# …
# 2, 2, 2, 2]),
# …
# ‘target_names’:array(['setosa', 'versicolor', 'virginica'],
# …
# 'DESCR': '.. _iris_dataset:
# ...
# 'feature_names':
# ...sklearn.datasetsがscikit-learnに付属しているサンプルのデータセットになります。
順番に解説していきます。
[5.1, 3.5, 1.4, 0.2]のようなデータが150個続いています。こちらのひとつひとつがアヤメ1本を表します。
こちらのデータは「’sepal length (cm)’, ‘sepal width (cm)’, ‘petal length (cm)’, ‘petal width (cm)’」となっており、
「大きい花びらの長さ、大きい花びらの幅、小さい花びらの長さ、小さい花びらの幅」を表しています。
こちらも150個要素があります。0、1、2を要素としており、それぞれアヤメの種類を表しています。
0:セトサ種
1:バージカラー種
2:バージニカ種
今回利用するデータセットには各50個、計150個のデータが入っています。
ターゲットで定義した各花名が記載されています。
descriptionの略です。データセットの説明が書かれています。
4つの数値がそれぞれ何を表しているか記載してあります。
初めに必要なライブラリをインポートします。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score先ほどの例のようにデータセットを読み込みます。
iris_list = load_iris()機械学習をする際は学習用データとテスト用データに分割します。
学習用データを用いてモデルを作成し、テスト用データで正解率を求めることで、作成したモデルの精度を測ります。
今回は学習用データを7割、テスト用データを3割で作成しました。
x_train, x_test, t_train, t_test = train_test_split(
iris_list.data, iris_list.target, test_size=0.3, random_state=0)
print(len(x_train))# 105
print(len(x_test))# 45x_trainが学習用データ、x_testがテスト用データです。
元々のデータが150個なので7:3に分割できています。
train_test_splitの引数を紹介します。
学習データの中身が毎回変わると毎回学習モデルが異なり、結果も異なってしまうため、ランダムに抽出する要素を固定するために0を与えます。
モデルの構築は読み込んだRandomForestClassifierのインスタンスを作成するだけです。
次に作成したモデルに学習用データを与えます。与えるのは先ほどtrain_test_splitで作成したデータです。
作成したモデル.fitで学習用データを与えられます。
# 学習モデルを作成
model = RandomForestClassifier()
# 学習モデルにテストデータを与えて学習させる
model.fit(x_train, t_train)作成したモデルにデータを与えていきましょう。
初めに各テスト用データの種類を推測します。
# テストデータを与えて各データの種類を推測
test = model.predict(x_test)次にテストの解答とラベルを比較し、正答率を求めます。
# テストデータのラベルを与えて答え合わせ
score = accuracy_score(t_test, test)print(f"正解率:{score * 100}%")# 97.77777777777777%約98%という高い正答率で求められました。
ここまでのソースコードをまとめると以下のようになります。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
iris_list = load_iris()
x_train, x_test, t_train, t_test = train_test_split(
iris_list.data, iris_list.target, test_size=0.3, random_state=0)
# print(len(x_train))
# print(len(x_test))
# 学習モデルを作成
model = RandomForestClassifier()
# 学習モデルにテストデータを与えて学習させる
model.fit(x_train, t_train)
# テストデータを与えて各データの種類を推測
test = model.predict(x_test)
# テストデータのラベルを与えて答え合わせ
score = accuracy_score(t_test, test)
print(f"正解率:{score * 100}%")
ここからは回帰分析を作成していきます。
カリフォルニアにある住宅の家賃(USD)を求めてみましょう。
今回使用するデータの概要を説明します。基本的な構造はアヤメと同様ですが、大きく異なる点はデータが実際の値であることです。アメリカの国勢調査局が作成したデータで、以下のような構成になっています。
・データ件数:20640件
・データ次元数:8
・データ要素:下記表参照
| MedInc | 所得(中央値) |
| HouseAge | 築年数(中央値) |
| AveRooms | 部屋数(平均値) |
| AveBedrms | 寝室数(平均値) |
| Population | 人口 |
| AveOccup | 世帯人数(平均値) |
| Latitude | 緯度 |
| Longitude | 経度 |
基本的に先ほどの例と同様の手順で進めます。
基本的に必要なライブラリは先ほどと同様です。
今回は回帰分析を行うため、インポートする学習モデルが異なり、accuracy_scoreは不要になります。
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressorアヤメの例同様サンプルデータを読み込みます。
calofornia_list = fetch_california_housing()アヤメの例同様学習用データとテスト用データに分割しましょう。
x_train, x_test, t_train, t_test = train_test_split(
calofornia_list.data, calofornia_list.target, test_size=0.3, random_state=0)今回の例でも7:3に分割しモデルを作成していきます。
scikit-learnの特徴でもお伝えしたように、異なるモデルでも同様の記述ができます。
# 学習モデルを作成
model = RandomForestRegressor(random_state=0)
# 学習モデルにテストデータを与えて学習させる
model.fit(x_train, t_train)注意点として、回帰分析の場合は学習モデルにもrandom_state=0を与える必要があります。
こちらも先ほどの理由同様、毎回結果が変わるのを防ぐためです。
ここまではアヤメの例とほとんど同じでしたが、ここからは少し異なります。
精度の測定結果は、分類の場合正解不正解の2択です。しかし回帰の場合は数値の推測なので2択ではありません。
作成したモデルにテストデータと解答を与えて精度を測定します。
score = model.score(x_test, t_test)print(f"正解率:{score * 100}%") # 正解率:79.27924752368652%先ほどのような解答に選択肢がないので精度が落ちました。
回帰の場合目標精度が50%と言われています。今回のテストデータは要素が多かったのである程度精度が高い学習モデルができました。
ここまでのソースコードをまとめると以下のようになります。
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
calofornia_list = fetch_california_housing()
x_train, x_test, t_train, t_test = train_test_split(
calofornia_list.data, calofornia_list.target, test_size=0.3, random_state=0)
# 学習モデルを作成
model = RandomForestRegressor(random_state=0)
# 学習モデルにテストデータを与えて学習させる
model.fit(x_train, t_train)
score = model.score(x_test, t_test)
print(f"正解率:{score * 100}%") # 正解率:79.27924752368652%






 アジャイル開発 (9)
アジャイル開発 (9)