
リファクタリングをPythonで実践!基本手法とコード例・注意点まで
2023.09.07

Pythonのset型は、リスト型のような集合データの一種で、重複した値を持たないデータ型になります。
set型を扱えるようになると、効率よく配列関係のデータを処理できるようになりますので、基礎を習得しておきましょう。
一般的にはset型を学習する前に、リスト型とタプル型、辞書型を学ぶと思います。
辞書型は今回の比較からは省き、よく似ている「リスト」と「タプル」「set」を比較してみましょう。
各データ型の違いを一覧にすると以下のようになります。
| リスト | タプル | set | |
| 重複データの可否 | 可 | 可 | 否 |
| 追加・削除 | ◯ | ✖️ | ◯ |
| 順番維持 | ◯ | ◯ | ✖️ |
| 2重構造 | ◯ | ✖️ | ✖️ |
| 集合演算 | ✖️ | ✖️ | ◯ |
他のデータ型に比べ、set型の特徴としては、
・重複した値を持たない
・集合演算ができる
・データの順番は保持されない
という点でしょう。
プログラムで表現すると以下のようになります。
#リスト型
hello_list = ['こんにちは', 'まいど', 'おっす', 'チャオ', 'ウィッス', 'こんにちは']
print(hello_list)
print(type(hello_list))
#結果
['こんにちは', 'まいど', 'おっす', 'チャオ', 'ウィッス', 'こんにちは']
<class 'list'>#set型
hello_set = set(hello_list)
print(hello_set)
print( type(hello_set) )
#結果
{'チャオ', 'ウィッス', 'おっす', 'こんにちは', 'まいど'}
<class 'set'>リスト型の場合は、「こんにちは」が2回出力されていますが、set型の場合は1回です。また最初のhello_listで定義した順番と、set型の出力結果は違うことが確認できます。
set()とするだけで重複なしのデータになりますので、リスト型の重複なしでデータを処理したい場合に有効となるでしょう。リスト型と同じようにfor文でループ処理することも可能です。
また後述しますが、複数の集合データで共通する値だけ取り出したい時(積集合)や、片方にあってもう片方にないデータを取得したい場合(差集合)に便利なデータ型になります。

set型の使い方をご紹介します。
setオブジェクトの生成は、5パターン考えられます。
my_set = set()
print(type(my_set))
print(my_set)結果
<class 'set'>
set()my_set = set('hello')
print(type(my_set))
print(my_set)結果
<class 'set'>
{'o', 'l', 'h', 'e'}hello_set = set( ['こんにちは', 'まいど', 'おっす', 'チャオ', 'ウィッス', 'こんにちは'] )
print( type(hello_set) )
print(hello_set)結果
<class 'set'>
{'チャオ', 'ウィッス', 'おっす', 'こんにちは', 'まいど'}hello_set = set( ('こんにちは', 'まいど', 'おっす', 'チャオ', 'ウィッス') )
print( type(hello_set) )
print(hello_set)結果
<class 'set'>
{'チャオ', 'ウィッス', 'おっす', 'こんにちは', 'まいど'}
hello_set = set( {'normal':'こんにちは', 'kansai':'まいど', 'karate':'おっす', 'italy':'チャオ', 'yo-kai_watch':'ウィッス'} )
print( type(hello_set) )
print(hello_set)結果
<class 'set'>
{'normal', 'italy', 'kansai', 'yo-kai_watch', 'karate'}set()を使用するだけでset型を定義できていますね。
またset型に変更する前後で、要素の順序も変わっていることが確認できます。
リスト型のように、set型も要素数を確認できます。
hello_set = set( ['こんにちは', 'まいど', 'おっす', 'チャオ', 'ウィッス', 'こんにちは'] )
print( len(hello_set) )
print(hello_set)結果
5
{'チャオ', 'ウィッス', 'おっす', 'こんにちは', 'まいど'}元データは6つ要素がありましたが、「こんにちは」が重複しているため5つに減っていることが確認できます。
リスト型はappend()で要素を追加しますが、set型はadd()で要素を追加できます。
hello_set = set( ['こんにちは', 'まいど', 'おっす', 'チャオ', 'ウィッス', 'こんにちは'] )
hello_set.add('☆')
print(hello_set)結果
{'チャオ', 'ウィッス', 'おっす', '☆', 'こんにちは', 'まいど'}リスト型は柔軟に追加位置を設定できますが、set型は順不同なため追加位置を指定できない点を把握しておきましょう。
set型の要素を削除する方法は、一部削除と全削除の2メソッドが用意されています。
set型内の一部要素を削除します。
hello_set = set( ['こんにちは', 'まいど', 'おっす', 'チャオ', 'ウィッス', 'こんにちは'] )
hello_set.remove('ウィッス')
print(hello_set)結果
{'チャオ', 'おっす', 'こんにちは', 'まいど'}削除に指定した「ウィッス」と重複している「こんにちは」ひとつが、元のリストから削除されていることが確認できます。
set型の要素をすべて削除する場合は、clearメソッドを使用します。
hello_set = set( ['こんにちは', 'まいど', 'おっす', 'チャオ', 'ウィッス', 'こんにちは'] )
hello_set.clear()
print(hello_set)
print( type(hello_set) )結果
set()
<class 'set'>
ふたつもしくは複数の集合データを比較したい場合は、set型の集合演算を用いると処理が早いです。
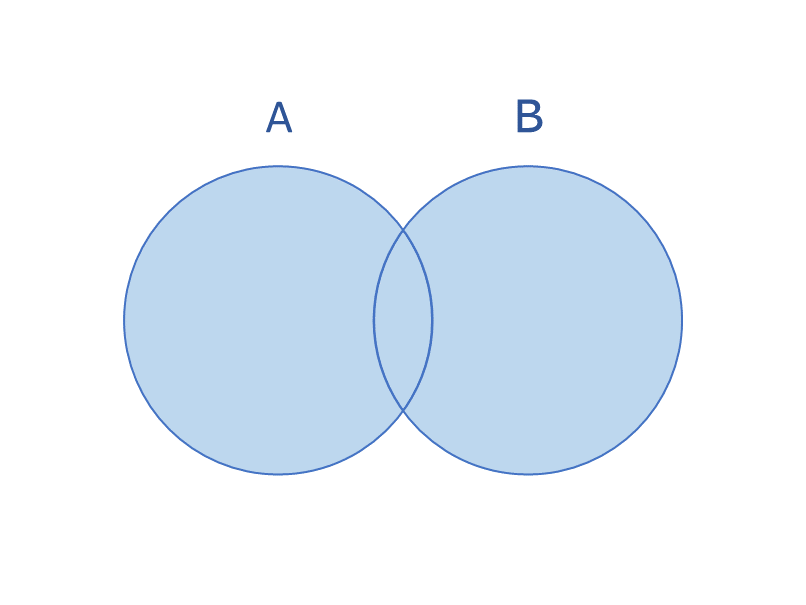
和集合は、複数の集合データにある要素全てを意味します。
A = set( ['牛乳', '卵', 'ホットケーキミックス', 'シロップ', 'バター', 'フライパン'] )
B = set( ['卵', '塩', 'コショー', 'フライパン'] )
AB = A | B
print(AB)結果
{'シロップ', '卵', '塩', 'コショー', '牛乳', 'ホットケーキミックス', 'バター', 'フライパン'}AとBの両方のデータが、ABに入ったことが確認できます。朝食に必要な物がリストアップできますね。
上記と同じ処理を、以下のように記述することもできます。
AB = A.union(B)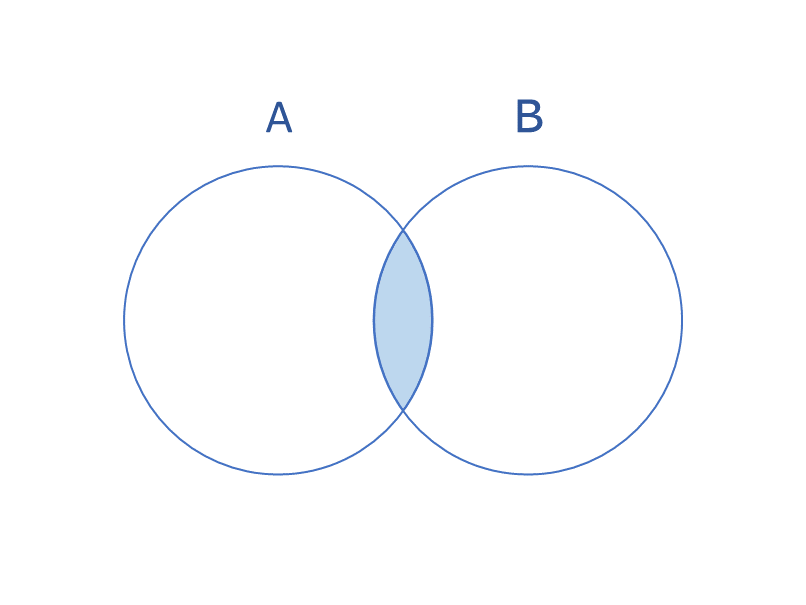
積集合は、複数の集合データから共通するデータのみを集めたものになります。
A = set( ['Tシャツ', '靴下', 'パンツ', '長ズボン', '長袖', 'ダウンジャケット'] )
B = set( ['Tシャツ', '靴下', 'パンツ', '半ズボン'] )
AB = A & B
print(AB)結果
{'Tシャツ', '靴下', 'パンツ'}AとBに共通する要素だけがABに入ったことが確認できます。ABのTシャツ、靴下、パンツはシーズン問わず必要ですよね。衣替えの時、何を残して、何をしまえばいいか、アルゴリズムが導いてくれます。
上記と同じ処理を、以下のように記述することもできます。
AB = A.intersection(B)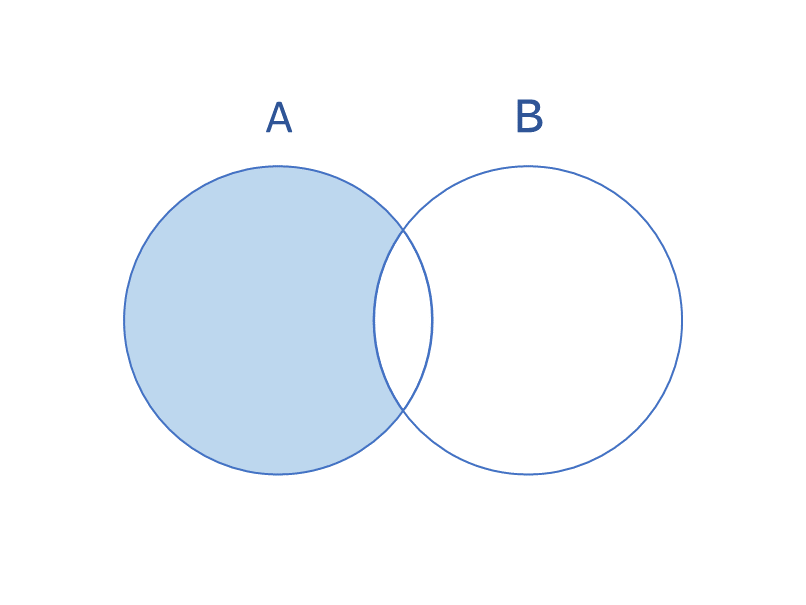
差集合は、どちらか一方には含まれているがもう片方には含まれていないデータになります。
A = set( ['テント', 'シート', '椅子', '折りたたみ机', 'コンロ', '網', 'トング'] )
B = set( ['テント', 'シート', '椅子', '折りたたみ机'] )
AB = A - B
print(AB)結果
{'トング', 'コンロ', '網'}AとBで重複する要素以外がABに入ったことが確認できます。みんなでキャンプに行く時、道具が重複することなくスマートなキャンプを楽しめますね。
ただし、
AB = B - Aと少ない方から多い方を引くと
set()と空の値がABに入りますので注意が必要です。キャンプの道具が足りなくなります。
上記と同じ処理を、以下のように記述することもできます。
AB = A.difference(B)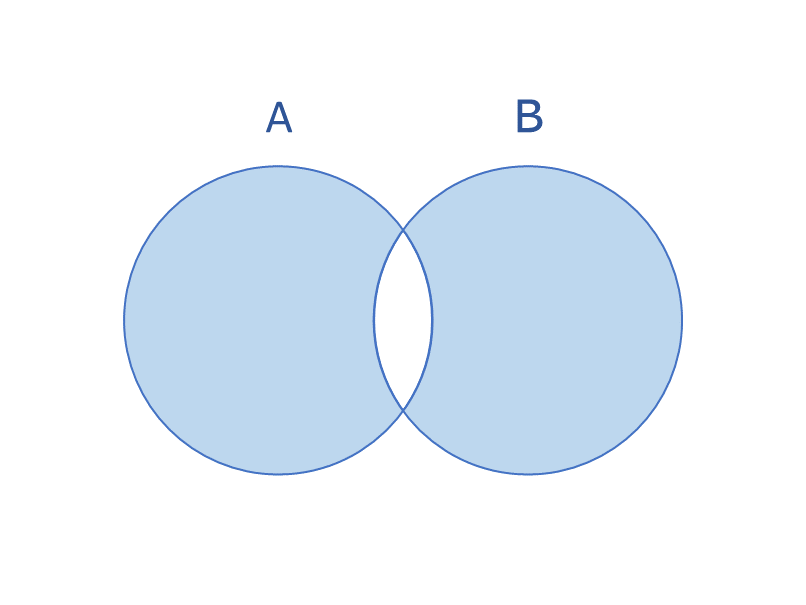
対称差集合は、複数の集合データの中で他と重複しない要素のみを抽出したデータになります。
A = set( ['ピカチュー', 'メッソン', 'ヒバニー', 'ゼニガメ', 'カメックス'] )
B = set( ['ピカチュー', 'ヒバニー', 'カイリュー'] )
AB = A ^ B
print(AB)結果
{'ゼニガメ', 'メッソン', 'カメックス', 'カイリュー'}AとBそれぞれが重複していないポケモンをリストアップできます。ポケモン交換などゲームの要素で活用できそうです。
上記と同じ処理を、以下のように記述することもできます。
AB = A.symmetric_difference(B)






 アジャイル開発 (9)
アジャイル開発 (9)