
リファクタリングをPythonで実践!基本手法とコード例・注意点まで
2023.09.07
Pythonで画像処理を行う際、必須になるのがOpenCVです。今回はOpenCVをわかりやすく紹介していきます。
各メソッドの利用例を載せていますので、ぜひ最後までご覧ください。

OpenCVとは「Open Source Computer Vision Library」の略です。画像や動画の処理ができる機能がまとめられたオープンソースライブラリです。元々はCやC++用のライブラリでしたが、Pythonでも使用できます。
OpenCVを利用するメリットとして以下が挙げられます。
・本格的な画像処理が可能
・コードが短くわかりやすい
・numpyなどの他のライブラリとの相性が良い
・エラーがわかりやすく、初心者でも触れやすい
windowsではpipで簡単にセットアップできます。コマンドプロンプトやパワーシェル、VSCodeなどのコマンドラインで以下のようにコマンドを実行してください。
pip install opencv-pythonこれだけで簡単にインストールできます。
Macの場合はhomebrewを用いてインストールします。
homebrewがインストールされていない方はこちらからインストールしてください。
homebrewインストール後は以下のようにコマンドを実行してください。
pip3 install numpy
brew tap homebrew / science
brew install opencv3 –with-python3 –without-python以上でインストールが完了します。
実行した際にエラーが発生してしまう場合はpipのバージョンが低い可能性があります。
pipのアップデート後に再度行ってください。
インストール完了後は正しくOpenCVがインストールできたか確認しましょう。実際に呼び出してみて、エラーがでないかを確認します。
以下のようにインポートしたファイルを実行してみましょう。
import cv2実行してエラーがでなければ適切にダウンロードできています。
ここからは画像処理を行うための基本的な操作を紹介します。
OpenCVをインポートし、各操作を行ってください。
import cv2OpenCVはcv2という形で呼び出します。各メソッドを利用する際にはcv2.~とします。
画像の読み込みにはcv2.imread()を使います。引数に画像のファイル名を指定します。
同じディレクトリにある場合はファイル名で指定できますが、異なるディレクトリにある場合は絶対パス、または相対パスを用いて指定してください。
パスが間違っていてもエラーにはならないので注意が必要です。
実際のコードを見てみましょう。
import cv2
path = "trainocamp.png"
img = cv2.imread(path)上記の手順で画像を読み込めます。画像のパスなどは変数に入れて書くことで可読性があがるので、変数を利用しましょう。
読み込んだ画像を表示するにはcv2.imshow()を利用しましょう。
cv2.imshow()を用いると別ウィンドウで読み込んだ画像を表示できます。
引数にウィンドウの名前、読み込んだ画像の指定が可能です。
また、cv2.imshow()を用いる場合は一般的に開いたウィンドウを削除する記述をします。
実際のコードを見てみましょう。
cv2.imshow('imshow_test', img)
cv2.waitKey(0) #待機時間、ミリ秒指定、0の場合はボタンが押されるまで待機
cv2.destroyAllWindows()cv2.waitKey()を入れることで任意の時間の間処理を止められます。waitKey()を入れなかった場合は一瞬で画像が閉じるので注意しましょう。destroyAllWindows()が実行されるとウィンドウが閉じます。
上記コードを実行し、表示したウィンドウが以下です。

指定した画像、ウィンドウ名を表示できました。
画像処理を行った場合の保存方法を紹介します。
保存するにはcv2.imwrite()を利用します。
第一引数に保存するファイル名、第二引数に保存したい画像を指定しましょう。
実際のコードを見てみましょう。
cv2.imwrite('save.png', img)上記コードで、操作したimgをsave.pngというファイルで保存できます。

ここからは読み込んだ画像に処理を施していきます。
文字列を描画するにはcv2.putText()を利用します。
実際のソースコードを見ていきましょう。
import cv2
path = "group_photo.jpeg"
img = cv2.imread(path)
cv2.putText(img,
"Hello Python",
org=(200, 50),
fontFace=cv2.FONT_HERSHEY_DUPLEX,
fontScale=1.5,
color=(0, 255, 0),
thickness=2,
lineType=cv2.LINE_AA)
cv2.imshow('image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()こちらが実行結果になります。

画面上部に指定した文字列が描写されました。
画像のトリミングは、画像インスタンスにサイズを渡してあげることで変更できます。実際のコードを見てみましょう。
import cv2
path = "trainocamp.png"
img = cv2.imread(path)
#画像の高さ
height = img.shape[0]
#画像の幅
width = img.shape[1]
# 画像サイズを取得
print(f"height:{height}, width:{width}")
# height:631, width:1201
# 画像をトリミング
tri_img = img[200: 500, 300: 600]
cv2.imwrite('trimming.png', tri_img)ご覧のように画像のインスタンスに値を与えることでトリミングを行えます。
今回の例では元々の画像サイズが高さ631px、幅1201pxでした。元の画像の高さ200pxから500px、幅300pxから600pxの箇所をトリミングしています。
・元の画像

・トリミング後の画像

※画像は拡大しています。トリミングしただけでは画像サイズは変わりません。
次にリサイズ方法を紹介します。リサイズにはcv2.resize()を利用します。リサイズを用いた変更方法は2種類あるので、ひとつずつ確認していきましょう。
はじめにサイズを指定して変更する方法を紹介します。実際のコードを見てみましょう。
import cv2
path = "trainocamp.png"
img = cv2.imread(path)
re1 = cv2.resize(img, dsize=(200, 200))
cv2.imwrite('resize1.png', re1)dsize=(高さ, 幅)という形でトリミングしています。上記コードで作成したresize1.pngはこちらです。

正方形にリサイズできています。
次に比率を指定して変更する方法です。実際のコードを見てみましょう。
re2 = cv2.resize(img, dsize=None, fx=1, fy=0.5)
cv2.imwrite('resize2.png', re2)fxで幅の比率、fyで高さの比率を変更しています。比率を指定してリサイズする場合はdsizeにNoneを与えてください。与えない場合はエラーが発生します。上記コードで作成したresize2.pngはこちらです。

高さの比率が半分になりました。
色空間とは、カラースペースとも呼ばれている特定の色を数値などのパラメータで表したものです。有名なところではRGBなどがあげられますが、OpenCVではBGRで読み込まれます。
しかし、画像処理によっては別のカラーにしたほうが処理がうまくいく場合があります。そのような場合には色空間の変換を行いましょう。
import cv2
path = "group_photo.jpeg"
img = cv2.imread(path)
# 画像処理のノイズ除去のため一旦グレースケールに変更
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)このような簡単なコードでグレースケール、つまり白黒写真に変換できます。グレースケールに変換することで画像処理のノイズが減り、誤認識を減らせます。
変換前の画像、変換後の画像は以下です。


ご覧のように白黒写真に変換できています。
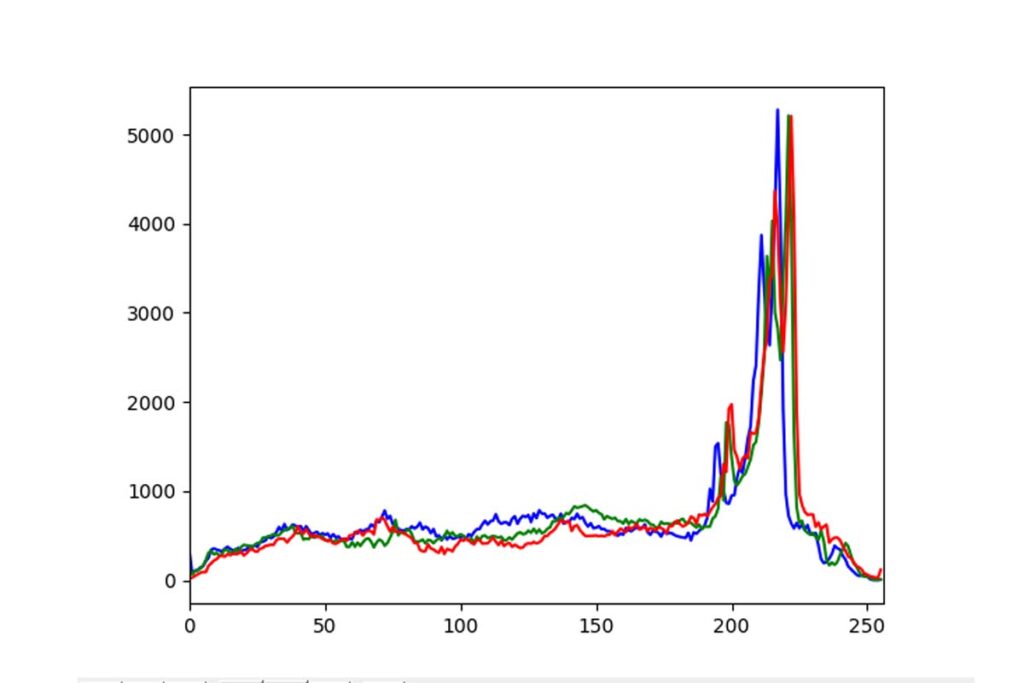
画像のヒストグラムを求めるにはcv2.calcHist()を利用します。cv2.calcHist()関数を利用することで、引数に渡した画像を色相分府の行列に変換します。実際のソースコードを見ていきましょう。
import cv2
import numpy as np
from matplotlib import pyplot as plt
path = "group_photo.jpeg"
img = cv2.imread(path)
color = ("b", "g", "r")
for i, col in enumerate(color):
histr = cv2.calcHist(images=[img], channels=[i],
mask=None, histSize=[256], ranges=[0, 256])
plt.plot(histr, color=col)
plt.xlim([0, 256])
plt.show()ご覧のようにfor文で三原色の色相分布を表現しています。ソースコードのように各パラメータにラベルを与える必要はありません。第一引数は[img]だけでも問題なく動きます。今回のソースコードではmatplotlibを利用して可視化を行いました。
元の画像と実行結果を見てみましょう。
・元の画像

・実行結果
輪郭検出にはcv2.findContors()を利用します。引数に二値化画像、検索モード、輪郭検出方法のフラグを指定することで実行できます。
二値化した際におちてしまう箇所の輪郭は取得できないので、ご注意ください。
実際のソースコードを見ていきましょう。
import cv2
path = "circle.png"
img = cv2.imread(path)
# 画像処理のノイズ除去のため一旦グレースケールに変更
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 白黒に変換
ret, thresh = cv2.threshold(img_gray,
120, 255, cv2.THRESH_BINARY_INV)
cv2.imwrite("change1.png", thresh)
# 輪郭検出
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(img, contours, -1, (0, 0, 255), 10)
cv2.imwrite("change2.png", img)今回の例では画素が120以上なら白、それ以下は黒に変換しています。
実行結果はこちらになります。
・元画像

・change1.png

・change2.png

ご覧のように輪郭を検出できました。
円を検出するのは簡単です。OpenCVのHoughCircles()を利用することで見つけることができます。早速ソースコードを見ていきましょう。
import cv2
import numpy as np
path = "circle.png"
img = cv2.imread(path)
# 画像処理のノイズ除去のため一旦グレースケールに変更
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 円を検出
circles = cv2.HoughCircles(img_gray, cv2.HOUGH_GRADIENT, dp=0.8, minDist=50, param1=100, param2=60, minRadius=0, maxRadius=0)
# numpyを用いて描画できる形に変換
circles = np.uint16(np.around(circles))
# 円が見つかるかで条件分岐
if len(circles):
for circle in circles[0, :]:
# 円周を描画
cv2.circle(img, (circle[0], circle[1]), circle[2], (0, 0, 255), 10)
# 中心点を描画
cv2.circle(img, (circle[0], circle[1]), 2, (0, 0, 255), 5)
cv2.imshow('img', img)
cv2.waitKey(0)
else:
print('見つかりませんでした')cv2.HoughCircles()はたくさんの引数を取ります。引数に与えた値で結果が異なるので、先に上記コードの実行結果を見てみましょう。
・元の画像

・円の検出結果画像

正しく円を検出しています。
ここからはcv2.HoughCircles()の引数がなにを表しているのかを紹介します。
こちらは画像データです。今まで同様処理したい画像を渡します。今回はグレースケールに変更した画像を渡しています。
こちらではハフ変換の手法を渡しています。
詳しいことはドキュメントにも記載されていません。このように記述するものと考えて、cv2.HOUGH_GRADIENTを渡しましょう。
こちらは検出基準です。こちらの値が小さいほど検出が厳しくなります。
大体のケースで0.8から1.2くらいの値を利用します。
2などの大きい値を渡してしまうと誤検出が増えてしまい、0だとエラーになるので注意しましょう。
こちらは検出される円がどれだけ離れていなければならないかを決める値です。
この引数を小さくすると同じ円でたくさん検知してしまいます。
先ほどの例では50としていましたが、20で実行してみましょう。
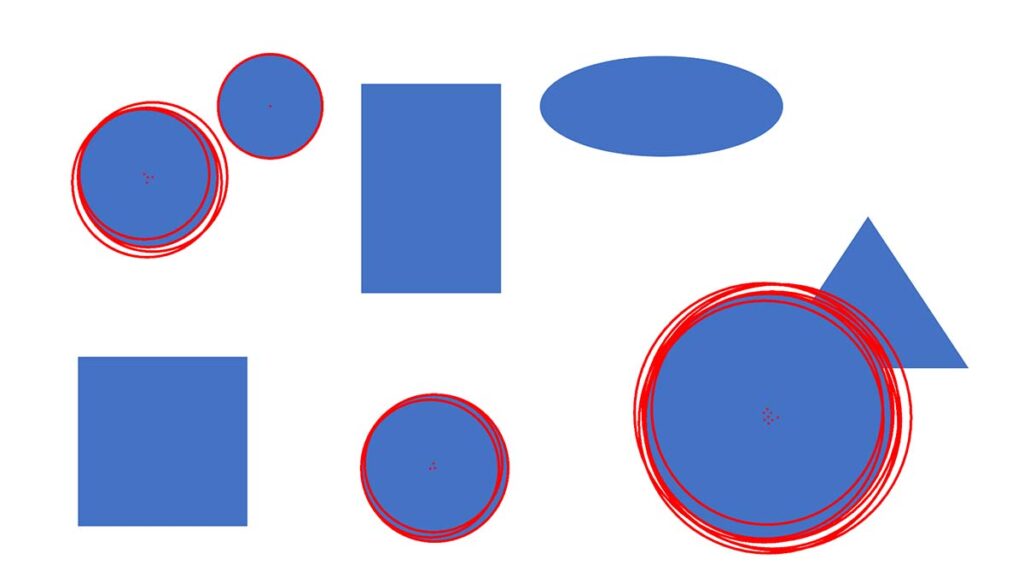
ご覧のように同じ円に対して複数検出(重複検出)されています。複数検出されてしまった場合はこちらの値を調整しましょう。
こちらはCanny法のHysteresis処理閾値です。
Canny法によるエッジ検出なので上限値以下、下限値以上のものはエッジとして判断します。Canny法に用いる上限値がparam1、下限値はpram1の1/2になります。
エッジ検出の細かな調整を行いたい場合はこちらの値を調整しましょう。
よくわからない方は100を渡せば問題ないです。
こちらは円の中点を検出する閾値です。
param2を小さい値で設定すると円の誤検出が増えてしまいます。
また、小さい値にしすぎると円を円と認識しないことが増えます。
処理する画像に応じてどのくらいの値にするか調整し、重複検出や未検出が少なくなるように調整していきましょう。
こちらは引数名の通り、検出する円の半径の下限値になります。
試しに300にして実行してみましょう。

ご覧のように左上の円がひとつ検知されなくなりました。このように半径の下限値を設定できます。
maxRadiusは半径の上限値になります。
設定した値より大きい半径の円が検出されなくなります。
最後に顔を検出する方法を紹介します。顔検出には顔検出をする学習データが必要になります。
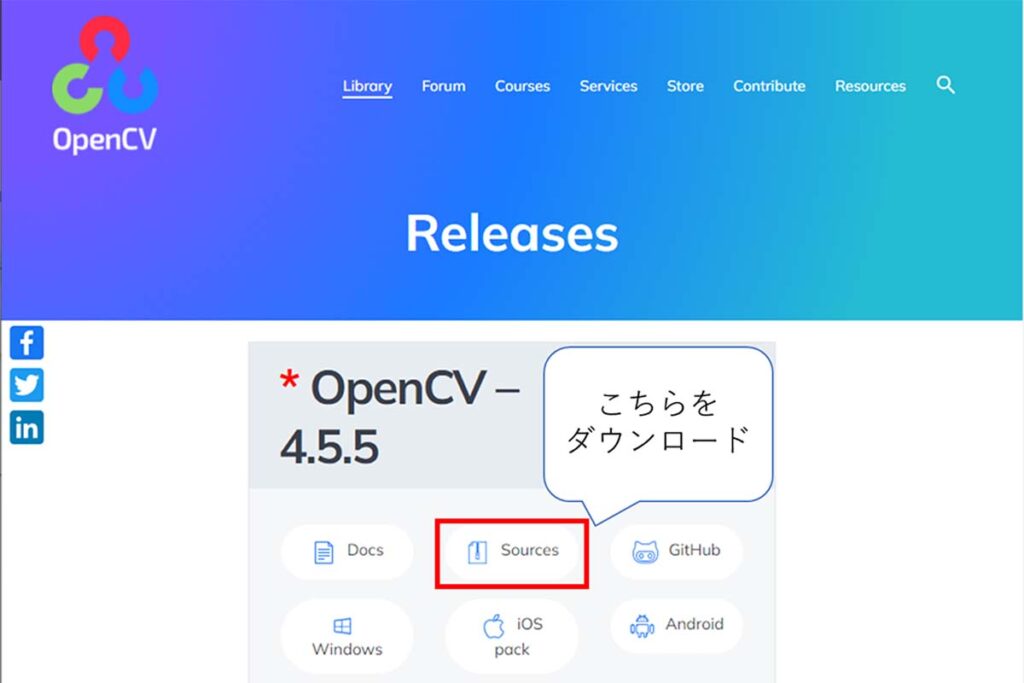
しかし、初心者の方が学習済モデルを作成するのは厳しいですよね。OpenCVを作成しているIntelが提供してくれているので、こちらからダウンロードしましょう。
以下のようなページに遷移したら、四角で囲われている箇所をクリックしダウンロードします。
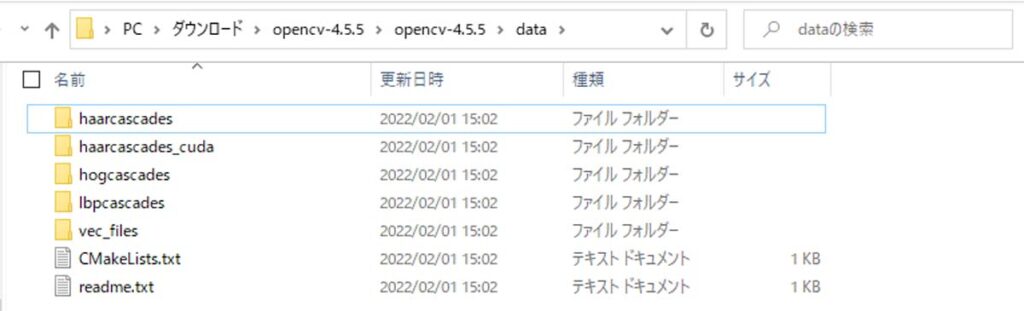
ダウンロード後はファイルを解凍し、上記ファイルパスの箇所からhaarcascadesというフォルダをPythonファイルと同じディレクトリに移してください。
これで準備完了です。
早速ソースコードを見ていきましょう。
import cv2
path = "group_photo.jpeg"
# 学習モデルのパス
cascade_path = './haarcascades/haarcascade_frontalface_alt.xml'
img = cv2.imread(path)
# 画像処理のノイズ除去のため一旦グレースケールに変更
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#グレースケールの表示
cv2.imshow('img', img_gray)
cv2.waitKey(0)
#学習済みモデルの読み込み
cascade = cv2.CascadeClassifier(cascade_path)
# 顔の検出
# minSizeで最小検出サイズを指定(今回は20*20以下は探さない)
face_list = cascade.detectMultiScale(img_gray, minSize = (20, 20))
# 顔が見つかるかで条件分岐
if len(face_list):
for (x,y,w,h) in face_list:
# 顔が見つかった場合赤い四角で囲う
cv2.rectangle(img, (x,y), (x+w, y+h), (0, 0, 255), thickness=3)
cv2.imshow('img', img)
cv2.waitKey(0)
# 顔が見つからなかった場合
else:
print('見つかりませんでした')今までの例より難易度があがったので混乱されている方も多いでしょう。流れを図示しました。コードで書くと複雑ですが、流れは単純です。
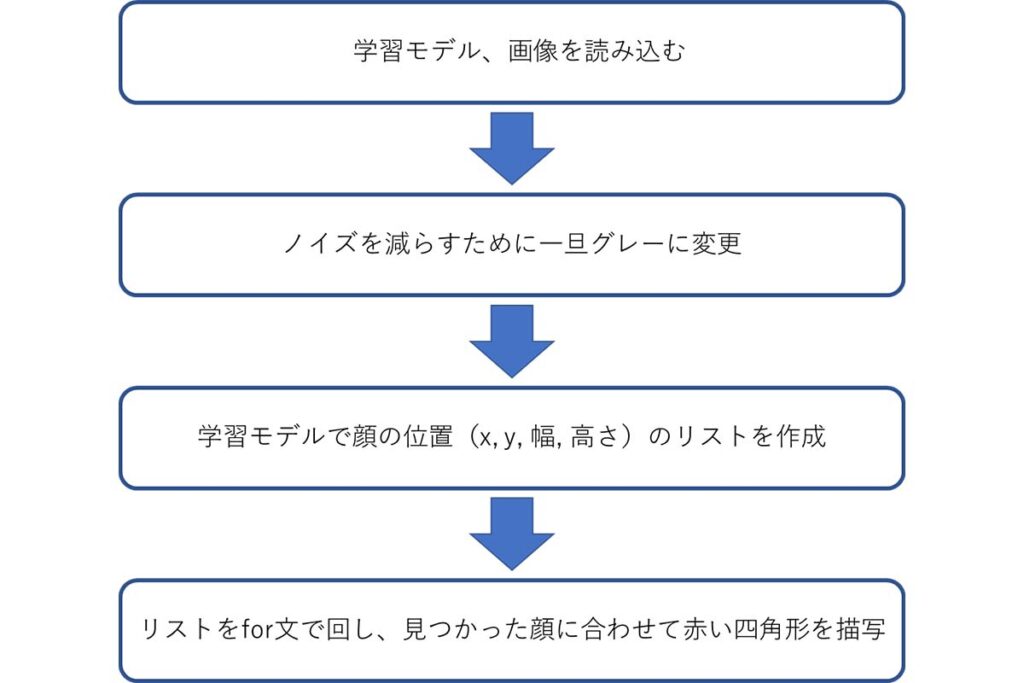
流れを確認したところで実行結果を見ていきます。
・元の画像
・顔検出結果

今回は一人検出できませんでしたが、他の方の顔に合わせて四角形を描写できました。







 アジャイル開発 (9)
アジャイル開発 (9)