
Spring 5でできることは?4からの変更点や互換性について解説
2022.09.30
Spring Batch は、Javaバッチ開発を効率的に開発できるので、バッチ開発フレームワークのデファクトスタンダードとなっています。
「Spring Batchで開発するには?」
「Spring Batchの実装方法は?」
といった疑問に対して、本記事ではSpring Batch の環境構築から使い方までを中級者エンジニア向けに詳しく解説していきます。
※本記事で紹介するサンプルコードは、Java18で動作確認しています。

Spring Batchとは、Spring Frameworkを中心としたSpringプロジェクトのひとつで、バッチ開発用のフレームワークです。SpringがもつDIコンテナやトランザクション管理機能をベースとした、さまざまな特徴を持っています。
Spring Batchの特徴を順に説明します。
Spring Batchは、業務システム用バッチアプリケーションの開発を効率化するために設計された、軽量なバッチフレームワークです。
Spring Batchのライセンスは、Apacheライセンスバージョン2というライセンスです。営利・非営利を問わず、誰でも無料で利用でき、自由に利用・改変・再配布ができます。
この章では、Spring Batchでできることを具体的に説明していきます。
バッチ処理とは、「一定量のデータを集め、一括自動処理する」ための処理方法のことです。
バッチ処理は大量データを処理するので、処理し終えるまでに長時間かかることが予想されます。途中でエラーが発生したときに、すべての処理をやり直すと、運用スケジュールに影響が出てしまいます。
このような影響を抑えるために、Spring Batchではバッチ処理を定期的にコミットし、処理をリスタートする仕組みを構築できます。
Spring Batchでは、Jobを構成する処理のことをStepと呼びます。Stepの並列実行、直列処理を設定ベースで柔軟に実装できるのがSpring Batchの大きな特徴です。並列実行することにより、大量データに対して処理スループットが向上できます。
Spring Batchの機能では足りないときに、他Springプロジェクトの機能を利用できる点にも注目です。Spring Bootの機能であるScheduleアノテーションを利用することで、任意の時間でバッチを実行できます。
大量データを扱うバッチ処理が異常終了したとき、エラーデータの修復後、エラーデータから処理を簡単にリトライできます。
ここで、Spring BatchとSpring Bootとの違いを説明します。
Spring Bootとは、Spring Frameworkを効率よく使えるようにしたSpringプロジェクトのひとつです。Spring Batchを使用しているからSpring Bootが使えないということではなく、Spring BatchとSpring Bootを組み合わせてアプリケーションを構築できます。
では、Spring Batchのアプリケーション構成を説明します。実際のアプリケーションを作るまえに、基本的な構成を把握しておくと、バッチ処理のポイントを押さえやすくなるでしょう。
バッチアプリケーションを起動するインターフェースです。すべてのバッチアプリケーションはこのクラスから起動されます。バッチアプリケーションにパラメーターを渡すことも可能です。
Job全体に関する設定の管理を行います。Jobはひとつ以上のStepから構成され、Stepの実行順序や実行方法を管理します。
Jobを構成する処理の単位で、ひとつのJobに複数のStepを持たせることが可能です。Jobを複数のStepに分割するメリットは、処理の再利用、並列化、条件分岐といった制御ができることです。Stepは、チャンクモデル、またはタスクレットモデルのいずれかの方式で実装します。
一定件数のデータごとにまとめて、入力(ItemReader)・加工(ItemProcessor)・出力(ItemWriter)の順で処理する方式です。Spring Batch側でインターフェースが提供されているので、プログラマーはそれぞれ実装することで、簡単に定型処理を作成できます。
チャンクモデルとは異なり、自由に処理を記述できる方式です。チャンクモデルの型に当てはまらない処理を実装したい場合、タスクレットモデルを使います。
たとえば、システムコマンドを実行したり、大量データの内1件だけ更新したりする場合などが考えられるでしょう。こちらもSpring Batchにインターフェースが用意されているので、プログラマーはインターフェースを実装します。
Stepにおけるチャンクモデルの処理を、データの入力、加工、出力にわけたインターフェースです。プログラマーはビジネスロジックをそれぞれに実装します。
データベースやファイルからデータの読み込み処理を行い、Javaオブジェクトへの変換を行います。
データの加工処理を行います。ItemReaderで読み込んだItemを、フィルタリング処理したりマッピング処理したりします。ItemProcessorは省略可能です。
ItemReaderやItemProcessorで処理されたItemを、データベースやファイルなどへ書き込む処理を行います。
JobRepositoryは、Jobの実行状態やStepの実行結果などをデータベースに保存する機能です。これらの管理情報は、指定されたデータベース上に保存されます。データベースに保存しないように設定することも可能です。

ここでは、Spring Batchの環境構築方法を見ていきましょう。本記事ではMacに環境構築する方法を解説します。
STSとは、Spring Tool Suiteの略で、Springベースのアプリケーション開発を行うために提供される統合開発環境です。
下記サイトからダウンロードしましょう。
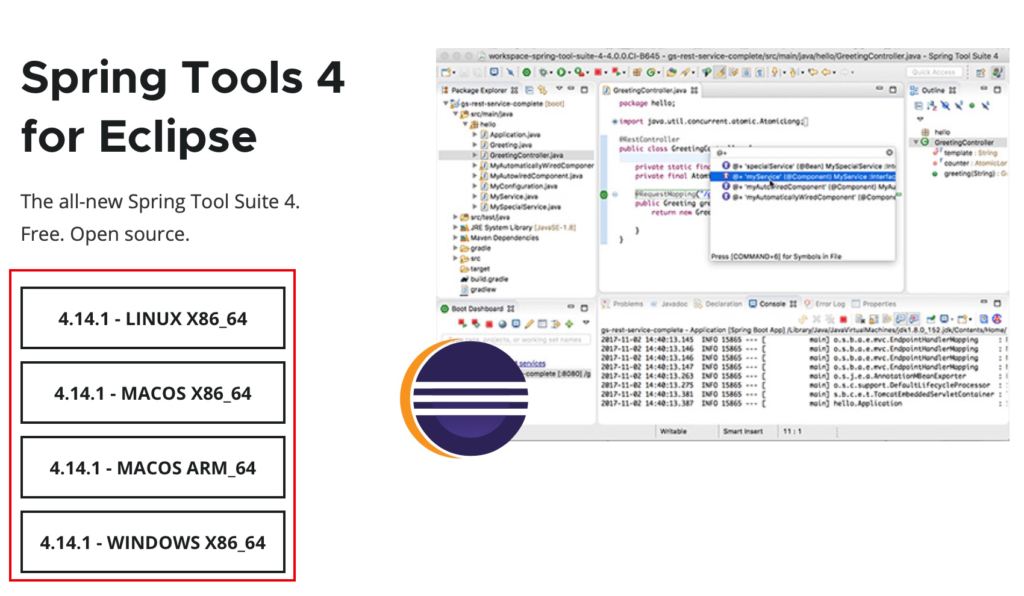
ご自身の環境に合わせてファイルを選択し、ダウンロードしてください。
ダウンロードしたファイルを実行し、STSをインストールします。
STSを日本語化しましょう。下記のサイトからダウンロードします。
https://mergedoc.osdn.jp/#pleiades.html
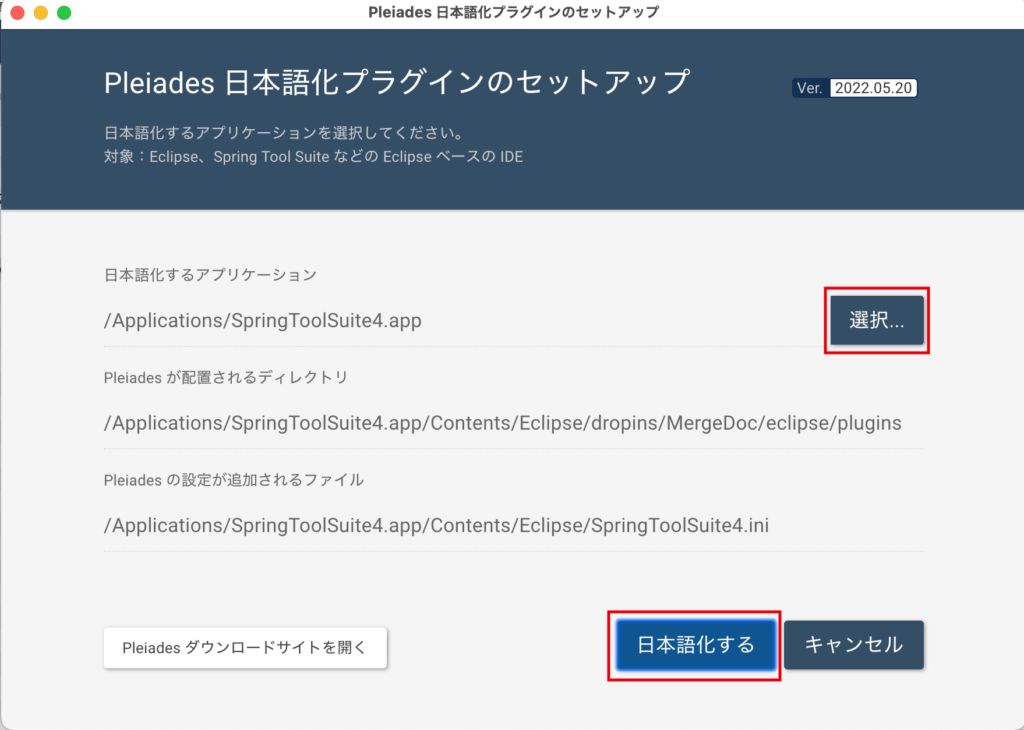
「選択」ボタンをクリックし、STSのファイルパスを指定しましょう。その後、「日本語化する」ボタンをクリックします。完了すると、STSが日本語化されます。
ここからはSpring Batchの使い方を紹介します。今回は、簡単なチャンクモデルでバッチプログラムを作ってみましょう。
まずは、プロジェクトを作成します。
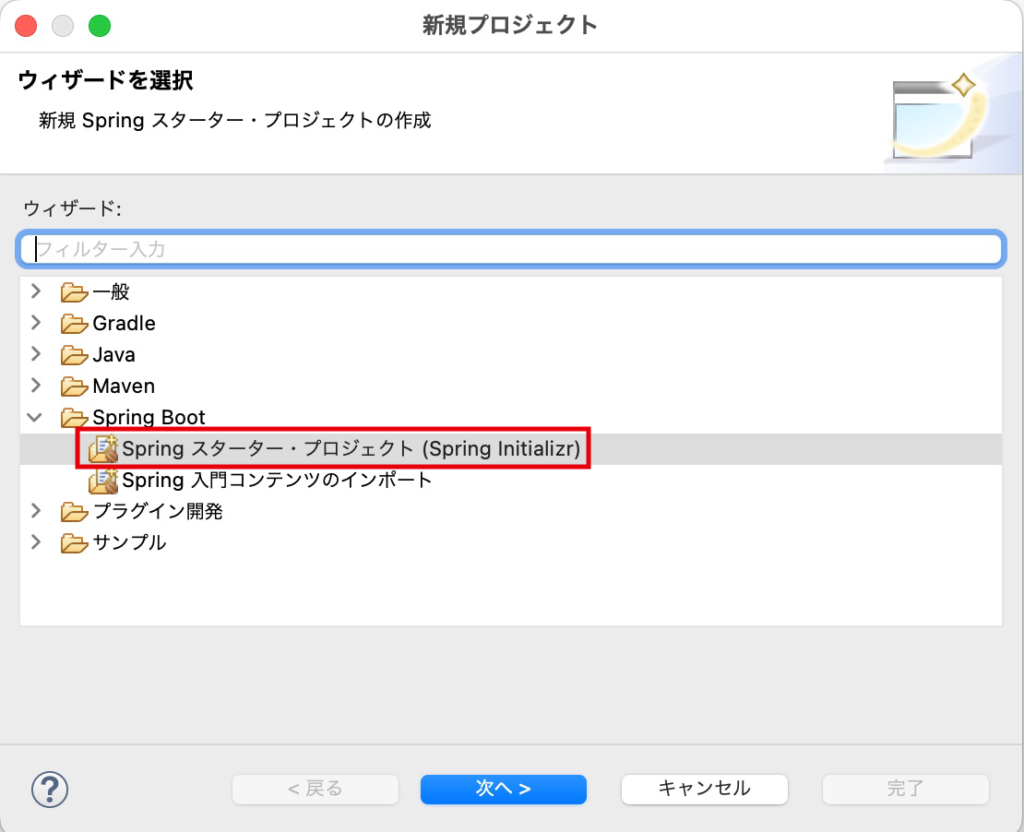
プロジェクト・エクスプローラーで、右クリックし、「新規」→「プロジェクト」を選択します。

「Spring Boot」→「Spring スターター・プロジェクト (Spring Initializr)」を選択し、「次へ」をクリックします。
名前に「BatchSampleChunk」と入力し、残りはそのままで、「次へ」をクリックします。
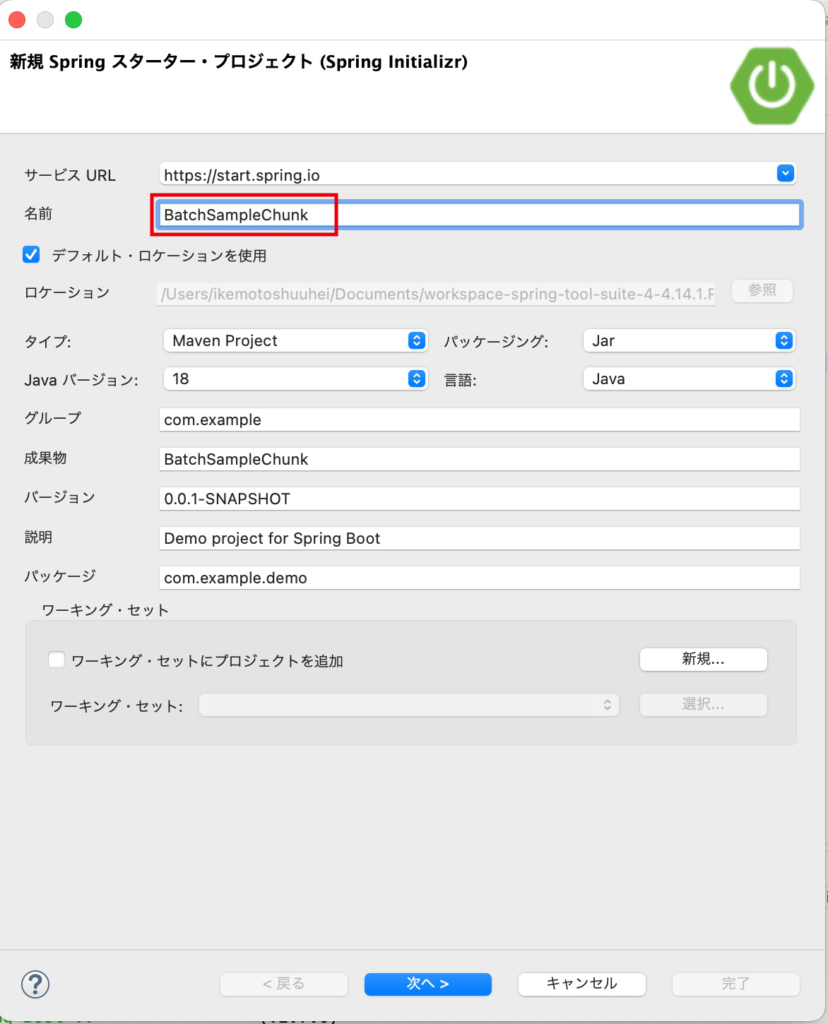
次に、プロジェクトの依存関係を選択します。
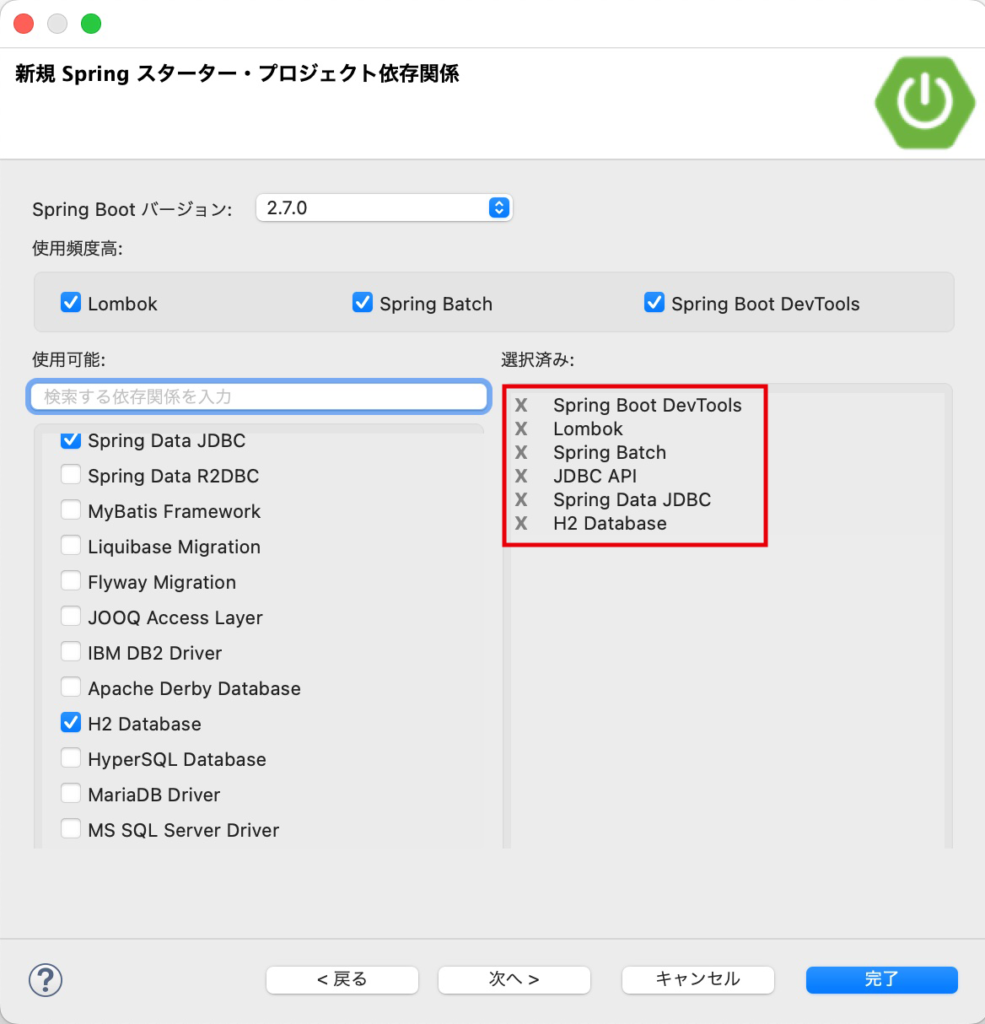
追加するライブラリは次の通りです。
| カテゴリ | 開発ツール | I/Q | SQL | |||
| ライブラリ | Spring Boot DevTools | Lombok | Spring Batch | JDBC API | Spring Data JDBC | H2 Database |
プロジェクト構成は以下の通りです。

今回作成するプログラムは、赤枠内のファイルです。以下に詳しく説明していきます。
最初に、Mainクラスを作成します。
package com.example.demo;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@EnableBatchProcessing
public class BatchSampleChunkApplication {
public static void main(String[] args) {
SpringApplication.run(BatchSampleChunkApplication.class, args);
}
}@EnableBatchProcessingアノテーションを付与し、SpringBatchを有効化します。
チャンクモデルのReaderを作成します。サンプルプログラムを確認してみましょう。
package com.example.demo.chunk;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.NonTransientResourceException;
import org.springframework.batch.item.ParseException;
import org.springframework.batch.item.UnexpectedInputException;
import org.springframework.stereotype.Component;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
@Component
@StepScope
@Slf4j
public class SampleReader implements ItemReader<String> {
Logger logger = LoggerFactory.getLogger(SampleReader.class);
//配列
private String[] input = {"Sunday","Monday","Tuesday","Wednesday","Thursday","Friday","Saturday"};
private int index = 0;
@Override
public String read() throws Exception,UnexpectedInputException,ParseException,NonTransientResourceException{
if (input.length > index) {
//配列の文字列を取得
String message = input[index++];
logger.info("Read:{}",message);
return message;
}
return null;
}
}ItemReaderインターフェースを実装しています。このサンプルコードでは、配列を順に読み取り、ログに出力しています。
次はProcessorを作成します。Readerから渡された文字列を加工します。
package com.example.demo.chunk;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.stereotype.Component;
import lombok.extern.slf4j.Slf4j;
@Component
@StepScope
@Slf4j
public class SampleProcessor implements ItemProcessor<String,String>{
Logger logger = LoggerFactory.getLogger(SampleProcessor.class);
@Override
public String process(String item) throws Exception{
//文字列の加工(小文字に変換)
item = item.toLowerCase();
logger.info("Processor:{}",item);
return item;
}
}ItemProcessorインターフェースを実装します。このサンプルコードでは、文字列を小文字に変換しています。
次はWriterを作成します。Processorから受け取った値をデータソースに出力します。
package com.example.demo.chunk;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.item.ItemWriter;
import org.springframework.stereotype.Component;
import lombok.extern.slf4j.Slf4j;
@Component
@StepScope
@Slf4j
public class SampleWritter implements ItemWriter<String>{
Logger logger = LoggerFactory.getLogger(SampleProcessor.class);
@Override
public void write(List<? extends String> items) throws Exception{
logger.info("writer:{}",items);
logger.info("=========");
}
}ItemWriterを実装します。ここでは、ログに出力する単純な処理にしています。
最後に、Batch設定クラスを作成します。
package com.example.demo.config;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@EnableBatchProcessing
public class BatchConfig {
//JobBuilderのFactoryクラス
@Autowired
private JobBuilderFactory jobBuilderFactory;
//StepBuilderのFactoryクラス
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Autowired
private ItemReader<String> reader;
@Autowired
private ItemProcessor<String, String> processor;
@Autowired
private ItemWriter<String> writer;
// ChunkのStepを生成
@Bean
public Step chunkStep() {
return stepBuilderFactory.get("SampleChunkStep") //Builderの取得
.<String, String>chunk(3) //チャンクの設定
.reader(reader) //readerセット
.processor(processor) //processorセット
.writer(writer) //writerセット
.build(); //Stepの生成
}
// Jobを生成
@Bean
public Job chunkJob() throws Exception {
return jobBuilderFactory.get("SampleChunkJob") //Builderの取得
.incrementer(new RunIdIncrementer()) //IDのインクリメント
.start(chunkStep()) //最初のStep
.build(); //Jobの生成
}
}stepBuilderFactoryメソッドを呼び出し、チャンクモデルのStepを作成します。chunkメソッドの引数で、一度に処理できる件数を指定できます。サンプルコードでは”3”を指定しました。
Spring Bootアプリケーションを実行し、ログを確認してみましょう。
: Started BatchSampleChunkApplication in 1.584 seconds (JVM running for 2.385)
: Running default command line with: []
: Job: [SimpleJob: [name=SampleChunkJob]] launched with the following
: Executing step: [SampleChunkStep]
: Read:Sunday
: Read:Monday
: Read:Tuesday
: Processor:sunday
: Processor:monday
: Processor:tuesday
: writer:[sunday, monday, tuesday]
: =========
: Read:Wednesday
: Read:Thursday
: Read:Friday
: Processor:wednesday
: Processor:thursday
: Processor:friday
: writer:[wednesday, thursday, friday]
: =========
: Read:Saturday
: Processor:saturday
: writer:[saturday]
: =========
: Step: [SampleChunkStep] executed in 40ms
: Job: [SimpleJob: [name=SampleChunkJob]] completed with the following parameters: [{run.id=1}] and the following status: [COMPLETED] in 56ms今回のサンプルコードでは、chunkメソッドの引数を”3”に指定しているので、
・Read×3回
・Processor×3回
・Writer×1回
を配列数分、繰り返し処理しているのがわかりますね。







 アジャイル開発 (9)
アジャイル開発 (9)