
Gradleとは何者?インストール方法〜使い方までわかりやすく解説
2022.09.02

Javaの文字列はStringクラスのインスタンスであり、参照型の変数です。
データ型は下の表のように基本型と参照型の2つに分かれています。
| 基本型 | 参照型 |
| 数値型(int型、long型など) boolean型 char型 | クラス型(String型、List型など) 配列型(int[]型など) |
基本型は変数に値をそのまま代入しますが、参照型は変数に代入するオブジェクトのメモリ上の場所を格納する型です。
String型はクラス型であるにもかかわらずimportしなくても使えたり、初期化の際にnew演算子が必要なかったりと、代入だけならば基本型のように扱えます。
しかし構造は参照型であるため、文字列を扱う際には少し注意が必要です。
文字列に対してよく行う操作のひとつに比較があります。
文字列比較の操作は、基本的にはStringクラスのequalsメソッドを使って行われます。しかし、なぜequalsメソッドを使うのか、equalsメソッドで行う比較と==演算子で行う比較との違いはどこにあるのかを理解しているでしょうか。
これらの比較方法について解説していきます。
前述のとおり、equalsメソッドで文字列比較を行うのが基本です。equalsメソッドを使えば文字列の「値」同士を比較できるからです。
equalsメソッドは以下のように使います。
文字列1.equals(文字列2)等しければtrue、等しくなければfalseが返ります。
それでは実際にequalsメソッドを使った例を見てみましょう。
public class Java_string {
public static void main(String[] args) {
String s1 = "あいうえお";
String s2 = "あいうえお";
String s3 = "かきくけこ";
System.out.println(s1.equals(s2));
System.out.println(s1.equals(s3));
}
}出力:
true
falses1、s2、s3はそれぞれの値の参照先(メモリ上の場所)を持っています。しかしequalsメソッドで比較するのは参照先ではなく、”あいうえお”、”かきくけこ”の値自体なので、s1とs2は等しく、s1とs3は異なる値である、という結果になります。
int型などの基本型なら==演算子で行える「値」同士の比較が、参照型であるStringではequalsメソッドを使って行われるのです。
==演算子での文字列比較は適切ではありません。なぜなら、equalsメソッドは文字列の値を比較するのに対して、参照型に==演算子を使うと参照先を比較するからです。
参照先とは”あいうえお”など文字列のオブジェクトがある「メモリ上の場所」であり、値が一緒であっても参照先も必ず同じになるわけではありません。
試しに==演算子での比較を行ってみましょう。
String s1 = "あいうえお";
String s2 = "あいうえお";
String s3 = "かきくけこ";
System.out.println(s1.equals(s2)); // equalsメソッドで比較
System.out.println(s1 == s2); // ==演算子で比較出力
true
true出力はtrue、すなわちs1とs2の参照先は等しいという結果になりました。
別々に初期化したはずなのになぜ参照先まで等しいのか、疑問を持つ人もいるのではないでしょうか。これは、格納するのが同じ文字列ならば、自動的に同じ文字列を参照する、という機能があるためです。
今回の例で考えてみましょう。
まず、s1は文字列”あいうえお”で初期化されます。”あいうえお”という文字列のオブジェクトはまだ存在しないため、オブジェクトが生成され、これを参照します。
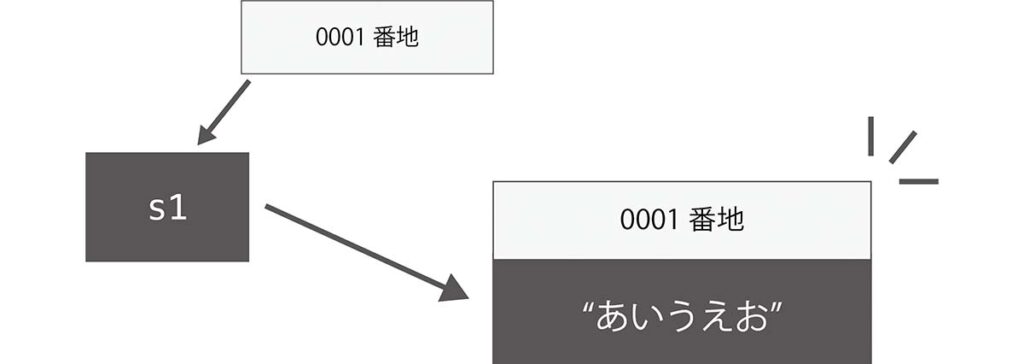
次にs2も同じ文字列”あいうえお”で初期化をします。このとき、”あいうえお”と同じ文字列のオブジェクトがあるか探します。s1で生成されたオブジェクトが見つかるので、s2もそのオブジェクトを参照するのです。
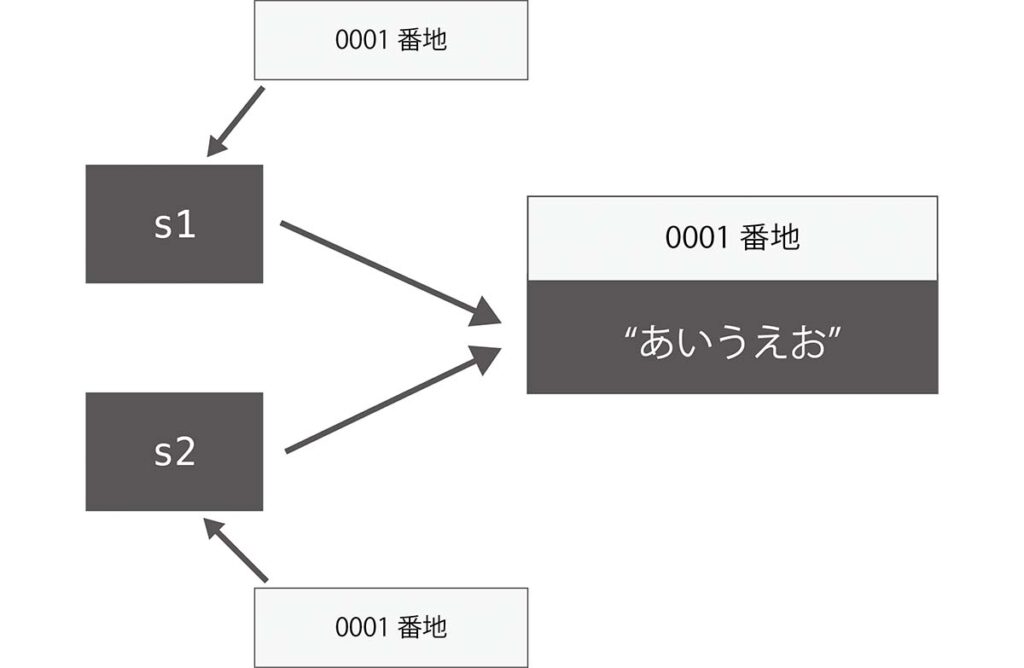
結局同じオブジェクトを指すならば、==演算子でも問題ないのでは?と思うかもしれません。しかし、同じ文字列でも違うオブジェクトを指す場合もあるのです。次の例を見てみましょう。
String s1 = "あいうえお"; // 普通に初期化
String s2 = "あいうえお"; // 普通に初期化
String s3 = "かきくけこ";
String s4 = new String("あいうえお"); // new演算子を使いインスタンスを生成
System.out.println(s1 == s4); // ==演算子で比較
System.out.println(s1.equals(s4)); // equalsメソッドで比較出力:
false
trues1、s2はStringの基本的な初期化方法でいつも通り初期化し、s4はnew演算子を使って新しく”あいうえお”オブジェクトを生成しています。
これにより、s4は明示的に新しく”あいうえお”オブジェクトを生成することを指定しています。つまり、既に”あいうえお”オブジェクトが存在していても関係なく新しいオブジェクトを生成するのです。
そのためs1とs4は異なるオブジェクトを参照していることになり、==演算子を使うとfalseとなってしまいます。
このように、==演算子を使うと初期化方法によって結果が変わってしまうことが分かりました。プログラムが予期せぬ動作をする原因にもなるので、文字列の値を比較するときにはequalsメソッドを使うようにしましょう。
実は、equalsメソッドを使う際に注意が必要な場合があります。
equalsメソッドの使い方は以下の通りでした。
文字列1.equals(文字列2)文字列1からequalsメソッドを呼び出し、文字列2との比較を行う、という流れになっています。
equalsメソッドはStringクラスのメソッドであり、メソッドを呼び出す側である文字列1もString型である必要があります。このため、String型であるはずの文字列1がnullであるとき、メソッドを呼び出せなくなってしまうのです。
例を見てみましょう。
String s1 = "あいうえお";
String s5 = null;
System.out.println(s1.equals(s5)); // false
System.out.println(s5.equals(s1)); // NullPointerException が発生nullであるs5からequalsメソッドを呼び出そうとすると、NullPointerExceptionという例外が発生してしまいました。しかしそれ以降の処理を続けるためにも、何らかの方法で例外を防がなければなりません。
どのような方法があるのか見ていきましょう。
==演算子でnullかどうかの判定を行ってから使用する方法があります。
呼び出す側がnullの場合は比較を行わず、nullでない場合のみequalsメソッドを使うことにより、例外の発生を防げます。
例を見てみましょう。
String s1 = "あいうえお";
String s5 = null;
if(s5 == null){
System.out.println("s5はnullです");
}else{
System.out.println(s5.equals(s1));
}
出力:
s5はnullです今まで使ってきたequalsメソッドはStringクラスのものでしたが、Objectsクラスにもequalsメソッドが存在します。
Objects.equalsメソッドはnullの比較ができる上、参照先ではなく値で比較をしてくれます。比較を行った例を見てみましょう。
import java.util.Objects; // import忘れずに
public class Java_string {
public static void main(String[] args) {
String s1 = "あいうえお";
String s2 = "あいうえお";
String s4 = new String("あいうえお");
String s5 = null;
String s6 = null;
System.out.println("(1)" + Objects.equals(s5, s1)); // (1) s5がnull
System.out.println("(2)" + Objects.equals(s5, s6)); // (2) s5、s6共にnull
System.out.println("(3)" + Objects.equals(s2, s1)); // (3) 同じオブジェクト
System.out.println("(4)" + Objects.equals(s4, s1)); // (4) 違うオブジェクト、同じ文字列
}
}出力:
(1)false
(2)true
(3)true
(4)trueまず、java.util.Objectsのimportを忘れずに行いましょう。
(1)はnullと文字列”あいうえお”の比較です。例外なども起こらず、falseが出力されます。
(2)ではnullとnullの比較が行われ、trueが出力されました。null同士の比較でもtrueになるのはObjects.equalsの特徴です。
(3)は同じオブジェクトを参照している2つを比較しました。もちろんtrueが出力されます。
そして(4)では、参照先が違うけれど同じ文字列である2つを比較しています。Objects.equalsは前述のとおり値で比較するので、trueが出力されました。

Stringクラスには、equalsメソッド以外にも多くの便利なメソッドがあります。場合に応じて使い分けていきましょう。
このメソッドは大文字と小文字を区別せず比較できます。使い方は以下の通りです。
文字列1.equalsIgnoreCase(文字列2)では実際に使ってみましょう。
String s7 = "hello";
String s8 = "Hello";
System.out.println(s7.equals(s8)); // equalsメソッドで比較
System.out.println(s7.equalsIgnoreCase(s8)); // equalsIgnoreCaseメソッドで比較出力:
false
trueequalsメソッドではfalseが出力され、equalsIgnoreCaseメソッドではtrueが出力されました。大文字と小文字を区別せずに比較できていることがわかります。
compareToメソッドでは、2つの文字列の大小を比較できます。この大小とは辞書的なもので、文字列のUnicode値によって比較されます。使い方は以下の通りです。
文字列1.compareTo(文字列2)先ほどまでは戻り値がboolean型でしたが、今回のcompareToメソッドではint型が返ってきます。どのような値になるのか、下の表で確認してみましょう。
| 文字列2が先(小さい) 文字列1が後(大きい) | 正の値(文字列1 – 文字列2) |
| 文字列1 = 文字列2 | 0 |
| 文字列1が先(小さい) 文字列2が後(大きい) | 負の値(文字列1– 文字列2) |
文字列の先、後とは辞書順のことです。appleとbananaなら辞書順ではappleが先、bananaが後に出てきます。
文字列1 – 文字列2において計算する値は、文字列によって異なります。実際にどんな値を計算しているのかは、Javaのドキュメント(https://docs.oracle.com/javase/jp/8/docs/api/java/lang/String.html#compareTo-java.lang.String-)を読んでみてください。
では実際に使った例を見てみましょう。
String s7 = "hello";
String s8 = "Hello";
String s9 = "apple";
String s10 = "banana";
System.out.println(s9.compareTo(s10)); // 辞書では appleの方が先、bananaが後
System.out.println(s7.compareTo(s8));出力:
-1
32辞書ではappleが先、bananaが後に来ます。呼び出す側(文字列1)が先にくる場合なので、上の表では3行目に当たり、負の値が返ることになります。
次に、helloとHelloを比較しました。Unicodeでは大文字が先、小文字が後なので、正の値が返ってきます。
compareToIgnoreCaseメソッドでは、大文字小文字を区別せず、辞書順で大小を比較できます。使い方は以下の通りです。
文字列1.compareToIgnoreCase(文字列2)戻り値は先ほどのCompareToメソッドと同じです。
では使っていきましょう。
String s7 = "hello";
String s8 = "Hello";
String s9 = "apple";
String s10 = "banana";
System.out.println(s9.compareToIgnoreCase(s10)); // 辞書では appleの方が前、bananaが後
System.out.println(s7.compareToIgnoreCase(s8)); // helloとHelloを比較出力:
-1
0appleとbananaは元からどちらも小文字だったので、先ほどと同じ結果になりました。helloとHelloの比較では、大文字小文字の区別がなくなり、同じ文字列なので0が出力されます。
regionMatchesは、文字列の範囲を指定して比較できます。まずは使い方をみてみましょう。
文字列1.regionMatches(大文字小文字の区別を無視するか, 文字列1の範囲の開始位置, 文字列2, 文字列2の範囲の開始位置, 文字数)引数が多くわかりにくいと思いますので、使い方を以下の例に沿って説明していきます。
String s9 = "apple";
String s11 = "Apple";
String s12 = "This is apple.";
System.out.println(s9.regionMatches(0, s12, 8, 5)); // (1) apple と This is apple. を比較
System.out.println(s11.regionMatches(0, s12, 8, 5)); // (2) Apple と This is apple. を比較
System.out.println(s11.regionMatches(true, 0, s12, 8, 5)); // (3) 大文字小文字を区別せず、Apple と This is apple. を比較
出力:
true
false
true下の図は(3)の例を図示したものです。
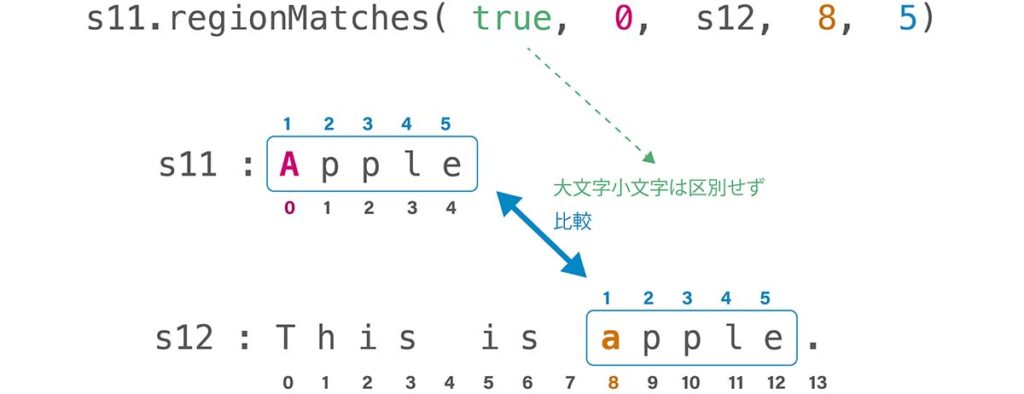
1つ目の引数は大文字小文字の区別を無視するかどうかを指定します。区別を無視する場合はtrue、区別したい場合はfalse、または何も書きません。
大文字小文字の区別している場合が(1)と(2)です。(1)は小文字と小文字の比較ですが、(2)は大文字のAppleと小文字のappleを比較するためfalseになっています。
(3)は1つ目の引数にtrueを入れることによって、大文字と小文字を区別せず比較しています。
2つ目の引数は呼び出す側の、比較する範囲の開始位置です。(3)ならs11の比較をどこから始めるか、何番目の文字かを入力します。0番目から開始しますので注意してください。
3つ目の引数は比較する文字列で、(3)ではs12です。
4つ目の引数は比較する文字列の、比較する範囲の開始位置です。(3)ではs12の比較をどこから始めるかを入力します。画像の通り8番目から比較を始めます。
5つ目の引数は開始位置から何文字分比較するかを示します。(3)なら5文字分比較するということです。これは呼び出す側、比較する側どちらも共通です。
containsメソッドは、文字列を含むかどうかの判定ができます。使い方は以下の通りです。
文字列1.contains(文字列2)文字列1に、文字列2が含まれるかを判定します。実際に使ってみましょう。
String s9 = "apple";
String s11 = "Apple";
String s12 = "This is apple.";
System.out.println(s12.contains(s9)); // appleを含んでいるか
System.out.println(s12.contains(s11)); // Appleを含んでいるか出力:
true
false大文字、小文字の区別がされるので、appleは含む、Appleは含まない、という判定になります。
startsWithメソッドは、文字列の最初が一致しているかを判定できます。使い方は以下の通りです。
文字列1.startsWith(文字列2, 比較開始位置)文字列1が文字列2から始まるかどうかを判定します。比較開始位置を指定すると任意の場所から判定できますが、入力しない場合は先頭が開始位置として判定されます。
開始位置は0から始まりますので注意してください。
実際に使った例を見てみましょう。
String s9 = "apple";
String s11 = "Apple";
String s12 = "This is apple.";
System.out.println(s12.startsWith(s9)); // appleから始まるか
System.out.println(s12.startsWith(s9, 8)); // 9文字目がappleから始まるか
System.out.println(s12.startsWith(s11, 8)); // 9文字目がAppleから始まるか出力:
false
true
falses12は”This is apple.”であり先頭はappleから始まりませんが、比較開始位置を9文字目からに指定すれば一致することが分かります。
大文字、小文字は区別されるのでAppleは一致しません。
endWithは、最後の文字列が一致しているかを判定できます。使い方は以下の通りです。
文字列1.endsWith(文字列2)文字列1の最後の文字列が文字列2と一致しているかどうかを判定します。
では実際に使ってみましょう。
String s9 = "apple";
String s11 = "Apple";
String s12 = "This is apple.";
String s13 = "This is apple";
System.out.println(s12.endsWith(s9)); // appleで終わるか
System.out.println(s13.endsWith(s9)); // appleで終わるか
System.out.println(s13.endsWith(s11)); // Appleで終わるか出力:
false
true
falses12は最後にピリオドがあるためfalseになりますが、s13はピリオドをなくしたためtrueになります。このメソッドも大文字小文字を区別するのでAppleは一致しません。
matchesは正規表現のパターンと一致するかを判定できます。使い方は以下の通りです。
文字列.matches(正規表現)正規表現とは、様々な記号を使って文字列のパターンを表現する方法です。
例えば.(ピリオド)は任意の1文字を表し、*(アスタリスク)は直前の文字を0回以上繰り返す場合を表現します。
これを組み合わせると .* となり、すべての文字列とマッチすることになります。
.* の正規表現で、実際にmatchesメソッドを使ってみましょう。
String s9 = "apple";
String s11 = "Apple";
String s12 = "This is apple.";
/*正規表現*/
String p1 = ".*le";
String p2 = ".*apple.*";
String p3 = ".*apple";
System.out.println(s9.matches(p1)); // (1) le で終わるか
System.out.println(s11.matches(p1)); // (2) le で終わるか
System.out.println(s12.matches(p2)); // (3) apple を含むか
System.out.println(s12.matches(p3)); // (4) apple で終わるか出力:
true
true
true
falsep1の正規表現は”.*le”、すなわち任意の文字列の後にleで終わる、という意味で、「〜le」または「le」にマッチします。endWithメソッドと同じ後方一致です。
p3の正規表現も同じように、appleで終わるパターンを表しています。「〜apple」、「apple」にマッチします。
p2の正規表現は”.*apple.*”で、appleの前後に任意の文字列がある、という意味になります。containsメソッドと同じことです。「〜apple〜」、「〜apple」、「apple〜」、「apple」にマッチします。
これらの正規表現とマッチするかどうかをmatchesメソッドを使って判定します。
(1)、(2)は、s9もs11も「〜le」の形なのでマッチしました。
(3)も、s12が「〜apple〜」の形なのでマッチしました。
(4)は、s12の「〜apple〜」という形が、p2のマッチする形である「〜apple」、「apple」と違うのでマッチしませんでした。
正規表現を使うと文字列のさまざまなパターンを表現できます。ぜひ調べて使ってみてください。







 アジャイル開発 (9)
アジャイル開発 (9)